
Talk about Go: Network programming about grouping and unpacking in TCP flow
As we all know, packet body transmission is an import part of network communication, whether it is the header or body of HTTP packets at the application layer, or the streaming data of TCP at the transport layer.
Foreword
Today, let’s talk about the topic of packet body transmission in network communication. This article will compare the common packet body analysis methods in network programming from several practical application examples.
Concept
Before entering the topic, let’s sort out the related concepts of TCP connections in the network. The packets in the network connection are like boats one after another in the river.

TCP Connection
The establishment of a network connection, a TCP connection is composed of four tuples, namely source IP + source port <-> target ip + target port , The bottom layer is composed of file descriptor, also known as fd, so without considering connection multiplexing, the number of single-machine connections will be limited by the number of available file descriptor.
Transmission format
After the connection is established, the server and the client will each send and receive the connection. Since interaction is involved, a transmission format must be agreed. For example, the language format of the communication between the two countries, AB, is the unified use of which country Language, the order of the sentence, such as subject-predicate-object, etc.
Serialization
After the transmission format is agreed, the data needs to be processed in the network transmission, because the computer prefers the binary byte stream, so it is what we often call serialization. The information after serialization is equivalent to compressing it, saving the network bandwidth.
A frequently discussed topic about serialization is big endian and little endian, which refers to whether to transmit the high-order byte address first or the low-order byte address first.
There is a corresponding API in Go to specify binary encoding/decoding:
// little endian: byte order starts with low address
var LittleEndian littleEndian
// big endian: byte order starts with high address
var BigEndian bigEndian
Write(buf, LittleEndian, &b1)
Read(buf, LittleEndian, &p)
Regarding the serialization method of binary big endian and little endian, you can see examples from the following Go open source projects:
BigCache: Local cache serialization
func wrapEntry(timestamp uint64, hash uint64, key string, entry []byte, buffer *[]byte) []byte {
keyLength := len(key)
blobLength := len(entry) + headersSizeInBytes + keyLength
// ...
binary.LittleEndian.PutUint64(blob, timestamp)
binary.LittleEndian.PutUint64(blob[timestampSizeInBytes:], hash)
binary.LittleEndian.PutUint16(blob[timestampSizeInBytes+hashSizeInBytes:], uint16(keyLength))
copy(blob[headersSizeInBytes:], key)
copy(blob[headersSizeInBytes+keyLength:], entry)
return blob[:blobLength]
}
grpc: Framed messages in a marked byte stream
// MakeFrame creates a handshake frame.
func MakeFrame(pl string) []byte {
f := make([]byte, len(pl)+conn.MsgLenFieldSize)
binary.LittleEndian.PutUint32(f, uint32(len(pl)))
copy(f[conn.MsgLenFieldSize:], []byte(pl))
return f
}
Packing and Unpacking
Whether in big-endian or little-endian mode, the information obtained from the serialized byte stream after deserialization is also called packet. The next step is to semantically parse the packet.
We all know that in a TCP stream, data packets are ordered, but in a pipeline of data, how does the application layer know the start and end of the data, that is, how to distinguish whether a certain piece of data belongs to the previous request or the next request , This is often referred to as unpacking and sticking. There are generally two solutions:
Tip 1: Agree on special separators
Let’s take a look at the usage scenarios. The most common case is like HTTP. Let’s see how it is agreed:
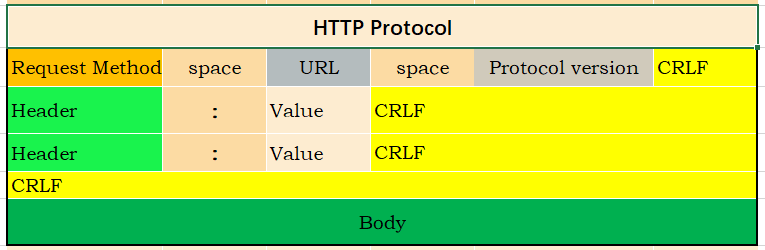 Use
Use CRLF(Carriage Return and Line Feed) as the delimiter,
- Separate request method, URL, and protocol by spaces
- Identified by
:as a key-value pair - If
:is not found, it means that the header parsing is over, and the nextCRLFis followed by the body.
We simulate a HTTP request, and use the WireShark software to capture and analyze the packet, and get the original text as follows:
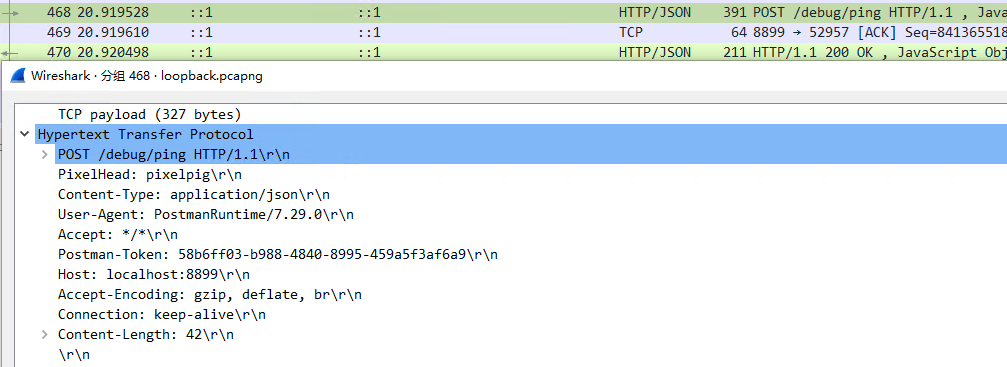 It can be seen that with
It can be seen that with \r\n as the delimiter, the segmentation rules are in line with the protocol standards. (Note: Because this is a standard HTTP protocol instead of HTTPS, it is not encrypted, so the transmitted message is displayed in clear text)
Another typical example is also commonly used, which is the Redis protocol. Let’s take a look at how Redis agrees:
Refer to RESP Official Protocol, Redis also uses \r\n as a separator, and each Redis command has a corresponding The prefix characters of ** are matched, which basically covers our daily needs of using Redis API.
- For Simple Strings, the first byte of the reply is “+”
- For Errors, the first byte of the reply is “-”
- For Integers, the first byte of the reply is “:”
- For Bulk Strings, the first byte of the reply is “$”
- For Arrays, the first byte of the reply is “*”
Redigo driver package
Let’s take a look at how Redis is parsed in the Go driver. The following code is quoted from the go-redis driver
const (
// convention prefix notation
ErrorReply = '-' // err type
StatusReply = '+' // simple type, such as "+OK\r\n"
IntReply = ':' // integer type
StringReply = '$' // string type
ArrayReply = '*' // array type, the number behind represents how many groups to bring
)
//...
func (r *Reader) ReadReply(m MultiBulkParse) (interface{}, error) {
line, err := r.ReadLine()
if err != nil {
return nil, err
}
switch line[0] {
case ErrorReply:
return nil, ParseErrorReply(line)
case StatusReply:
return string(line[1:]), nil
case IntReply:
return util.ParseInt(line[1:], 10, 64)
case StringReply:
return r.readStringReply(line)
case ArrayReply:
n, err := parseArrayLen(line)
if err != nil {
return nil, err
}
if m == nil {
err := fmt.Errorf("redis: got %.100q, but multi bulk parser is nil", line)
return nil, err
}
return m(r, n)
}
return nil, fmt.Errorf("redis: can't parse %.100q", line)
}
According to the unit test case, the Redis command is converted by the packet protocol, and the format in Go is as follows:
var writeTests = []struct {
args []interface{}
expected string
}{
{
[]interface{}{"SET", "key", "value"},
"*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n",
},
{
[]interface{}{"SET", "key", "value"},
"*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n",
},
{
[]interface{}{"SET", "key", int64(math.MinInt64)},
"*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$20\r\n-9223372036854775808\r\n",
},
{
[]interface{}{"SET", "key", durationArg{time.Minute}},
"*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$2\r\n60\r\n",
},
{
[]interface{}{"SET", "key", recursiveArg(123)},
"*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$3\r\n123\r\n",
},
{
[]interface{}{"ECHO", true, false},
"*3\r\n$4\r\nECHO\r\n$1\r\n1\r\n$1\r\n0\r\n",
},
}
The above is a case of packet restoration through special separators. Next, let’s look at another common solution.
Tip 2: Agree fixed interval rules, and then read according to the length
This is called TLV (type-lenth-value), type-length-value. As the name implies, it is the first contract type, the second one agrees on the length to be read, and the end subscript is obtained according to the length.
Sometimes type and length can be combined into one, for example, when type=1, the length is 3, when type=2, the length is 5, etc. According to the agreement between the server and the client, the agreement is as follows:

Before referring to the lightweight tcp server zinx framework implemented by go, which includes the encapsulation and disassembly of the packet body in network communication, the protocol agreed by this framework is TLV way, let’s take a look at its implementation details:
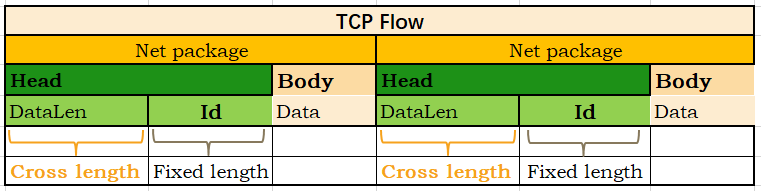
In the TCP flow, each network packet is divided into Head and Body, and each Head defines the data span and Business Id of the packet, the application layer can know the end subscript of Body according to the data span of the package when reading, so as to read the corresponding Data interval.
Code Example:
// Agreed on the structure of the Message body
type Message struct {
DataLen uint32
ID uint32
Data []byte
}
// NewMsgPackage create a message pack
func NewMsgPackage(ID uint32, data []byte) *Message {
return &Message{
DataLen: uint32(len(data)),
ID: ID,
Data: data,
}
}
// Packet method (compressed data)
func (dp *DataPack) Pack(msg ziface.IMessage) ([]byte, error) {
dataBuff := bytes.NewBuffer([]byte{})
//1. write dataLen
if err := binary.Write(dataBuff, binary.LittleEndian, msg.GetDataLen()); err != nil {
return nil, err
}
//2. write msgID
if err := binary.Write(dataBuff, binary.LittleEndian, msg.GetMsgID()); err != nil {
return nil, err
}
//3. write data body
if err := binary.Write(dataBuff, binary.LittleEndian, msg.GetData()); err != nil {
return nil, err
}
return dataBuff.Bytes(), nil
}
The above is the encapsulation of the message. Let’s see how to disassemble it on the reader side:
// header's fixed length span
var defaultHeaderLen uint32 = 8
func (dp *DataPack) GetHeadLen() uint32 {
//ID uint32(4 bytes) + DataLen uint32(4 bytes)
return defaultHeaderLen
}
// handling client requests
go func(conn net.Conn) {
// Create a packet unpacking object dp
dp := NewDataPack()
for {
// 1.read the head part of the stream
headData := make([]byte, dp.GetHeadLen())
_, err := io.ReadFull(conn, headData) // ReadFull will fill up msg
if err != nil {
fmt.Println("read head error")
}
// 2.Unpack the headData byte stream into msg
msgHead, err := dp.Unpack(headData)
if err != nil {
fmt.Println("server unpack err:", err)
return
}
// 3.when header span got length, reading the data
if msgHead.GetDataLen() > 0 {
msg := msgHead.(*Message)
msg.Data = make([]byte, msg.GetDataLen())
// Read byte stream from io according to dataLen
_, err := io.ReadFull(conn, msg.Data)
if err != nil {
fmt.Println("server unpack data err:", err)
return
}
}
}
}(conn)
References
RESP Protocol
Zinx TCP Communication Framework