
Talk about etcd (Part1): Hierarchy Overview with bird's eye view
etcd is very common in the field of microservices. This series will talk about what problems etcd solves and how it solves it for a step-by-step analysis.

Foreword
etcd is very common in the field of microservices. It is often used as a registry to provide service registration and discovery. For example, the K8S framework uses etcd as the basic component for internal interaction. Recently, I have been sorting out some internal structures and dependent components of etcd. Today, let’s take a look at the global perspective and talk about some technology stacks of etcd.
What problem does it solve
The positioning of etcd is a general consistent KV storage, but in application scenarios oriented to service registration and discovery, there are probably several ways to use it:
- Registration/configuration center KV storage
- Service Discovery
- Distributed lock
How it is solved
Layered design
Hierarchical design is the basic idea of software development. etcd also adopts module division of labor to implement each internal component separately, so as to perform their own duties, from the API layer to the logic layer, and then to the underlying file storage, which is roughly divided into three modules. , this series will be disassembled chapter by chapter based on this idea. This series will be divided into the following major modules for analysis, if you are interested, you can follow me and pay more attention :)
Conformance Protocol
When it comes to distributed storage, distributed protocols are naturally inseparable. The bottom layer of etcd relies on the raft consensus algorithm to ensure consistency, and adopts the election strategy to regularly update the current status of each node.
Way of communication
The communication method between etcd nodes is updated and iterative (v2->v3). v2 uses HTTP/1.X protocol and communicates based on RESTful API; v3 adds HTTP/2.x grpc protocol support on the basis of compatibility with v2. In the multiplexing scenario, the transmission efficiency is improved, based on Stream API with long connection for activity detection.
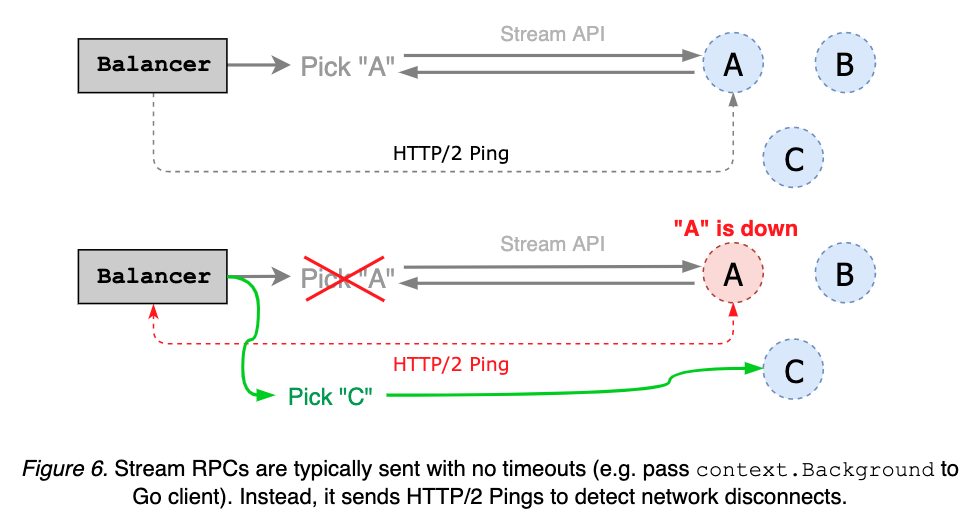 In addition, etcd exposes a friendly API to shield the underlying complex application logic and provide a logical cluster view of multiple physical machines.
In addition, etcd exposes a friendly API to shield the underlying complex application logic and provide a logical cluster view of multiple physical machines.
Data Storage
Regarding the underlying storage of etcd data, it mainly relies on the write-ahead log (WAL) and the BoltDB storage engine. All data will be guaranteed to be written to the WAL for data persistence before submission. The detailed implementation of BoltDB will be elaborated in the subsequent series, with these technical points:
- B+ tree, KV DB, “more reading and less writing”
- Combined with COW lock-free read and write concurrency
- mmap() (memory mapped disk technology), zero copy
Among them, etcd spends a lot of space on multi-version control of nodes (MVCC), which depends on the index mapping of the underlying B+ tree and the memory B-tree structure. How they are related will be discussed later in this series.
Mindmap
The entire technology stack of etcd can actually be expanded vertically and horizontally. Here is a diagram of the context. This series will be carried out in conjunction with this brain map. You can also make in-depth contact with the points of interest.
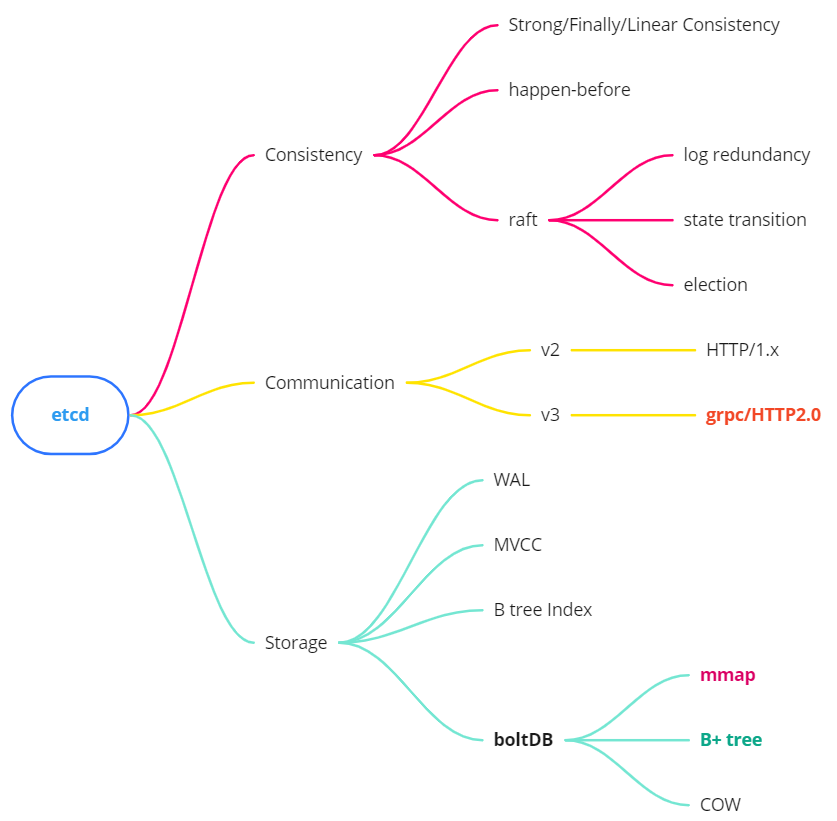
Reference link
- etcd docs
https://etcd.io/docs/v3.5/learning/ - Deep Dive: etcd
https://www.youtube.com/watch?v=DrtdrdwDpZE - raft pdf
https://raft.github.io/raft.pdf