
Talk about etcd (Part2): the raft consistency protocol
The purpose of the consensus algorithm is to maintain a consensus conclusion when there is an abnormality in the machine cluster to ensure the provision of services to the outside world.
Today, let’s talk about the consensus mechanism of etcd, the raft protocol.

What problem does it solve
Before entering etcd’s raft, let’s talk about what the consistency of distributed systems is and what problems the raft protocol solves.
Different Semantics of Consistency
In fact, in the ACID transaction characteristics, consistency as C is more like a kind of energy conservation or quality conservation, such as transfer, snap-up, and the amount of items will not disappear out of thin air or appear redundant.
In the distributed field, distributed consistency often refers to consensus, which means that multiple nodes reach an agreement (either everyone is wrong, or everyone is right), the difference is if it is under the semantics of ACID transactions Consistency, generally refers to strong consistency.
How it is solved
etcd internally achieves consistency through election and record synchronization.
etcd notifies each node of the update record. After more than half of the nodes get ack, the master node submits it and notifies other nodes to submit it together to achieve consensus data synchronization. In addition, the etcd log records every approved operation and periodically compresses the archive.
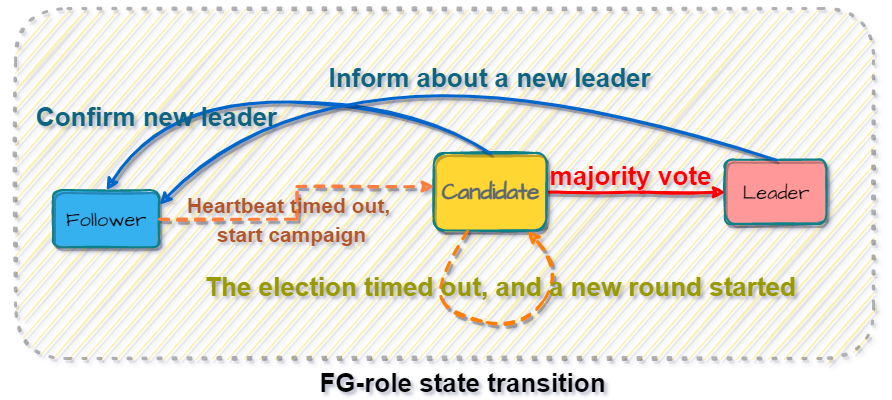
Elections and state transitions
In the raft protocol, each node has three role states, namely: Leader, Candidate, and Follower. Nodes update the status of each node through regular heartbeat detection and record synchronization. Each node has the awareness of being the leader. The leader sends a heartbeat with the follower regularly to inform that the term is not over. When the heartbeat times out or a network partition occurs, the follower will run for election, but there are some rules to follow:
- Leader must be generated by Candidate and get the majority of votes
- If there is an existing leader and the current leader’s term is the latest, the follower does not participate in the election
- When the leader’s heartbeat times out, the follower participates in the election and becomes a candidate, and records a vote for himself
- If the node’s log is older than the candidate’s log update time, the candidate’s voting request will be rejected
The state transition of the three roles is shown in the following figure [FG-role state transition]:
Log Replication
We know that the distributed storage function of etcd must involve the concept of multiple storage versions of data. How is the data version of each node of etcd synchronized?
etcd uses logs to record data. Each node has its own local log. These logs come from the leader’s synchronization and record the leader’s term number at that time, referred to as termId. This term number is used to distinguish the old and new versions of the log files. That is, if the node’s log is older than the candidate’s log update time, the candidate’s voting request will be rejected.
Once the new leader role takes office, the leader will synchronize the current log subscript that can be submitted to the follower. If a follower fails to keep up, the leader will send the last log subscript to the follower step by step, until the follower catches up with the alignment synchronization.
The log data format of each role is as follows, t represents the term number, and kv is a key-value pair.
Leader and Follower interact through MatchIndex and NextIndex, Follower will inform the Leader of the currently received maximum matching index MatchIndex, and the Leader will pass NextIndex to synchronize the latest node to the Follower.
The log diagram of each node is as follows:
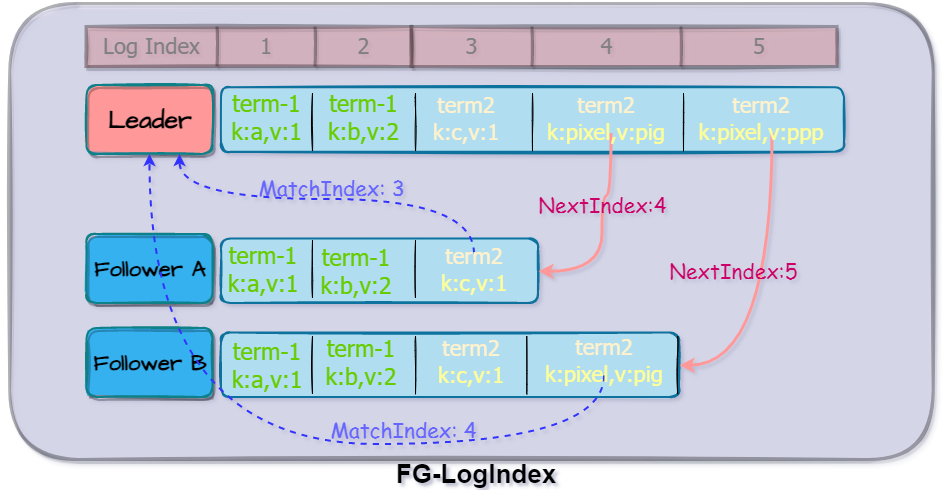
Through MatchIndex, the leader node can know the records that the current cluster has been recognized by most nodes, and can notify other followers to submit a block by broadcasting Msg.
The structure of the synchronization request body is as follows:
type Entry struct {
Term uint64 `protobuf:"varint,2,opt,name=Term" json:"Term"`
Index uint64 `protobuf:"varint,3,opt,name=Index" json:"Index"`
Type EntryType `protobuf:"varint,1,opt,name=Type,enum=raftpb.EntryType" json:"Type"`
Data []byte `protobuf:"bytes,4,opt,name=Data" json:"Data,omitempty"`
}
// AppendEntries RPC request: Attempt to sync record to node
func (r *raft) appendEntry(es ...pb.Entry) (accepted bool) {
li := r.raftLog.lastIndex()
for i := range es {
es[i].Term = r.Term
es[i].Index = li + 1 + uint64(i)
}
// Track the size of this uncommitted proposal.
if !r.increaseUncommittedSize(es) {
// The current log does not catch up with the Leader
r.logger.Debugf(
"%x appending new entries to log would exceed uncommitted entry size limit; dropping proposal",
r.id,
)
// Reject the new record of the leader, need to wait for catching up by majority
return false
}
// use latest "last" index after truncate/append
li = r.raftLog.append(es...)
r.prs.Progress[r.id].MaybeUpdate(li)
// Regardless of maybeCommit's return, our caller will call bcastAppend.
r.maybeCommit()
return true
}
Log Compression
Due to the incremental addition of the operation update log, the raft node will periodically archive and compress the log version after reaching an agreement, which is somewhat similar to the AOF and Snapshot backup strategies of Redis. One compression can free up space, reduce storage space and avoid a large number of operation logs. Replaying is also convenient for nodes that lag behind too many logs to quickly catch up with the leader.
Among them, raft startup will have an associated member storage to store the log data collection, and the specific related operations are implemented in the raft.Storage interface of etcd. The core members are as follows:
type bootstrappedRaft struct {
lg *zap.Logger
heartbeat time.Duration
peers []raft.Peer
config *raft.Config
// raft server associative storage implementation
storage *raft.MemoryStorage
}
//...
//Storage implement
type MemoryStorage struct {
sync.Mutex
hardState pb.HardState
snapshot pb.Snapshot
// ents stores the current node operation set, each Entry represents the log additional attributes
ents []pb.Entry
}
//Entry Additional properties
type Entry struct {
Term uint64 `protobuf:"varint,2,opt,name=Term" json:"Term"`
Index uint64 `protobuf:"varint,3,opt,name=Index" json:"Index"`
Type EntryType `protobuf:"varint,1,opt,name=Type,enum=raftpb.EntryType" json:"Type"`
Data []byte `protobuf:"bytes,4,opt,name=Data" json:"Data,omitempty"`
}
raft will periodically create snapshots to compress the log, which is equivalent to saving the snapshot to a local file, and then execute the Compact() function to rotate the ents field, and retain a new round of subscripts .
// Compact discards all log entries prior to compactIndex.
// It is the application's responsibility to not attempt to compact an index
// greater than raftLog.applied.
func (ms *MemoryStorage) Compact(compactIndex uint64) error {
ms.Lock()
defer ms.Unlock()
offset := ms.ents[0].Index
if compactIndex <= offset {
return ErrCompacted
}
if compactIndex > ms.lastIndex() {
getLogger().Panicf("compact %d is out of bound lastindex(%d)", compactIndex, ms.lastIndex())
}
i := compactIndex - offset
ents := make([]pb.Entry, 1, 1+uint64(len(ms.ents))-i)
ents[0].Index = ms.ents[i].Index
ents[0].Term = ms.ents[i].Term
ents = append(ents, ms.ents[i+1:]...)
ms.ents = ents
return nil
}
In fact, before committing MemoryStorage, the node will also write to the local disk for persistence. Once the fault occurs, the data can be reconstructed. This process is called the WAL write-ahead log.
More details on log storage will be discussed in etcd storage analysis of this series.
Network Partition Handling
We know that network node failures can actually happen. Here we divide it into two cases to analyze how to ensure consistency. Suppose there is a scenario as follow:
The client sends a request to the leader, and the leader is responsible for distributing data to the followers and submitting it after receiving approval from most nodes.
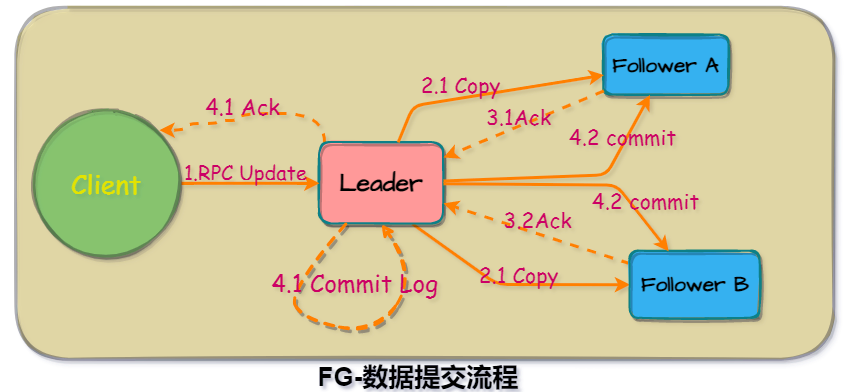
If the client update process fails, what will the different roles do?
- Follower failure: The leader will continue to confirm the follower record through RPC requests to catch up
- Leader failure:
The leader failure situation can be subdivided again. After the data log reaches the leader at the time of downtime, whether the follower submits two situations:
- The data arrives at the leader and is not submitted to the follower. At this time, the leader is down and the client does not receive an ACK. The retry logic will be enabled, and the consistency will continue to be guaranteed after the new leader recovers.
- The data reaches the leader and some followers have been submitted. At this time, the leader is down, and a new leader will be generated in the submitted followers because their records are up to date. Once again, the election is successful and becomes the new leader. Finally, consistency synchronization is performed. .
- The leader node has a network partition, and a “split brain” occurs in a short period of time, that is, the network partition cannot contact the other party, and two leaders are generated in two local networks. At this time, in another partition, a new leader will be selected. , the term number of the new leader is +1. After the network partition is restored, because the term number of the new leader is larger than that of the old leader, it will eventually be synchronized with the data version of the new leader with the largest TermId.
There is also an optimization option here. etcd provides aPreVoteparameter to optimize the situation of frequent leader elections due to network problems. If the current node wants to become a candidate candidate, there will be aPreCandidateas the state of pre-voting, if the pre-voting does not get a corresponding response from the majority of nodes, the election will be abandoned.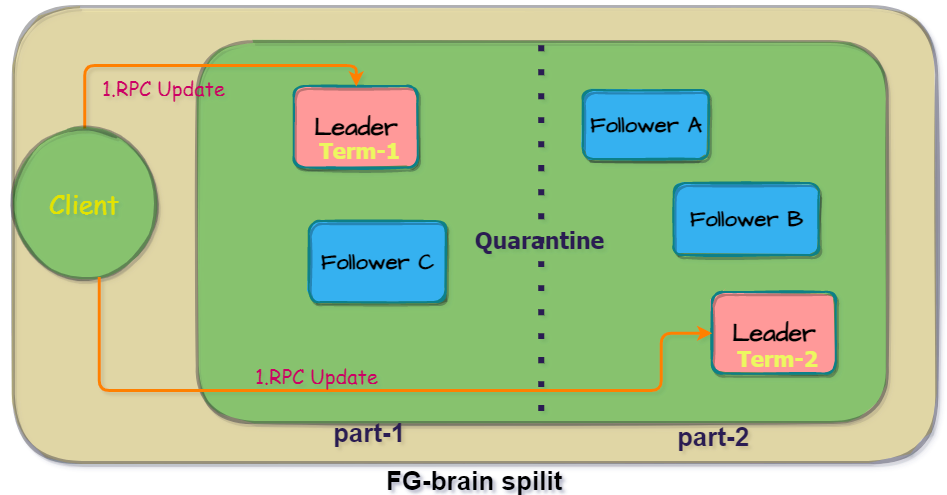
In addition, for split-brain scenarios, etcd also provides a switch for the Leader to check the votes itself.
// CheckQuorum specifies if the leader should check quorum activity. Leader
// steps down when quorum is not active for an electionTimeout.
CheckQuorum bool
Every once in a while, the leader obtains heartbeats from other nodes and records the number of connections. If the number of heartbeat connections is less than half, the leader will automatically drop to a follower.
// tickHeartbeat is run by leaders to send a MsgBeat after r.heartbeatTimeout.
func (r *raft) tickHeartbeat() {
// ...
// self checking
if r.checkQuorum {
if err := r.Step(pb.Message{From: r.id, Type: pb.MsgCheckQuorum}); err != nil {
r.logger.Debugf("error occurred during checking sending heartbeat: %v", err)
}
}
//...
}
// Leader msg handle
func stepLeader(r *raft, m pb.Message) error {
// These message types do not require any progress for m.From.
switch m.Type {
// ...
case pb.MsgCheckQuorum:
// ...
// Check if the leader has a majority vote
if !r.prs.QuorumActive() {
r.logger.Warningf("%x stepped down to follower since quorum is not active", r.id)
// reduced to Follower
r.becomeFollower(r.Term, None)
}
// ...
}
// ...
}
Linearizable Read
In the above network partition failure scenario, we know that there may be dual leaders for a period of time, that is, the data version may have dirty data. In fact, there is a maximum commit index CommitIndex on the etcd data set, which represents the current subscript recognized by most nodes, and ReadIndex represents the latest index that can be obtained by the current node (maybe not yet recognized by most).
Through these two records, etcd provides the option of whether to enable linear reading (Serializable bool type), which is used to block read requests.
When strong consistency is required, linear reading is enabled, and the request will wait until The Follower version ReadIndex catches up with the consistent subscript CommitIndex and returns the data. At this time, the read records can be guaranteed to be consistent in the cluster.
The relevant source code is as follows:
type RangeRequest struct {
// key is the first key for the range. If range_end is not given, the request only looks up key.
Key []byte `protobuf:"bytes,1,opt,name=key,proto3" json:"key,omitempty"`
// ...
// serializable sets the range request to use serializable member-local reads.
// Range requests are linearizable by default; linearizable requests have higher
// latency and lower throughput than serializable requests but reflect the current
// consensus of the cluster. For better performance, in exchange for possible stale reads,
// a serializable range request is served locally without needing to reach consensus
// with other nodes in the cluster.
Serializable bool
// ...
}
func (s *EtcdServer) Range(ctx context.Context, r *pb.RangeRequest) (*pb.RangeResponse, error) {
trace := traceutil.New("range",
s.Logger(),
traceutil.Field{Key: "range_begin", Value: string(r.Key)},
traceutil.Field{Key: "range_end", Value: string(r.RangeEnd)},
)
ctx = context.WithValue(ctx, traceutil.TraceKey, trace)
var resp *pb.RangeResponse
var err error
//...
if !r.Serializable {
// blocking waiting
err = s.linearizableReadNotify(ctx)
trace.Step("agreement among raft nodes before linearized reading")
if err != nil {
return nil, err
}
}
chk := func(ai *auth.AuthInfo) error {
return s.authStore.IsRangePermitted(ai, r.Key, r.RangeEnd)
}
get := func() { resp, err = txn.Range(ctx, s.Logger(), s.KV(), nil, r) }
if serr := s.doSerialize(ctx, chk, get); serr != nil {
err = serr
return nil, err
}
return resp, err
}
Summary
This is some understanding of etcd’s internal consensus mechanism in the past few days, mainly involving concepts such as election state transfer and log compression. The next chapter in this series will talk about how etcd nodes communicate.
Reference link
- raft MessageType
https://pkg.go.dev/go.etcd.io/etcd/raft/v3#hdr-MessageType - etc技术内幕 - 百里燊
- 云原生分布式存储基石etcd深入解析 - 华为云