
Talk about etcd (Part3): the Communication Protocol between Client and Server
As mentioned earlier, etcd implements each module through layers. This time we will enter the network part. Today, let’s talk about the communication way of etcd inside the server and client role.

What problem does it solve
Communication Efficiency
Talking about the communication protocol, of course, the communication method between nodes must be considered. The early etcd communication version is v2, which exposes external APIs through HTTP+JSON.
Because services often need to perceive changes in node configuration or monitor pushes, the client and the The server needs frequent communication. The early v2 used HTTP1.1 long connection to maintain, and the communication efficiency is still not high.
Since this article focuses on network communication, the upgrade features from v2 to v3 only focus on network communication-related functions, and other storage feature optimizations will be analyzed in the subsequent “underlying storage”, such as v3’s MVCC, snapshots, transactions, etc.
HTTP/1.X VS HTTP/2
Let’s briefly talk about the evolution from HTTP/1.x to HTTP/2:
Number of Connections
Before HTTP/2, HTTP/1 was not efficient, because the same request would block the sending of subsequent network packets while waiting for a response. Most of today’s network problems have changed from bandwidth to latency. Sometimes the benefits of increasing bandwidth (the size of the content sent) are not as good as reducing latency (time-consuming network transfers).
In addition, we cannot violently open multiple connections. After all, creating a connection based on the three-way handshake consumes resources. In addition, the blocking problem of a single connection has not been solved. Trying to open multiple connections to optimize is a temporary solution.
Text protocol
HTTP/1 uses a text protocol, its encoding format is friendly to humans, but the transmission is not efficient, and lack of security without HTTPS.
The etcd v3 version introduces the communication method of grpc+protobuf (based on HTTP/2.0), and its advantages are:
- Using binary compression for transmission, serialization/deserialization is more efficient
- Based on the HTTP2.0 server-side active push feature, the event multiplexing has been optimized
- The
Watchfunction uses grpc’s stream flow for perception. The same client and server use a single connection, instead of v2’s HTTP long polling detection, directly reducing the number of connections and memory overhead
Compatibility
In order to be upwardly compatible with the v2 API version, etcd v3 provides a grpc gateway to support the original HTTP JSON interface support.
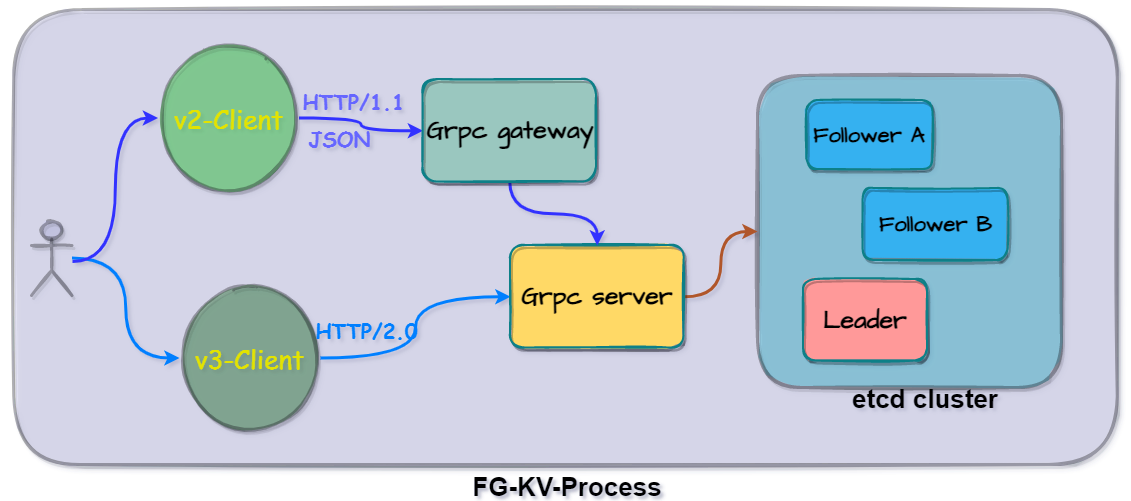
How it is solved
In the first part of this series, we talked about etcd splitting the functions of each module through layers and implementing them separately to improve code readability and reduce maintenance costs.
In the communication module, etcd also adopts a layered strategy, in which the network modules of external cross-machine nodes are concentrated in the package of api.rafthttp, and the node status update and underlying storage are distributed in etcd .raft package.
v2 Protocol Conversion
This is a transition logic for etcd v2 requests to transition to the underlying etcdserver:
// parseKeyRequest converts the received http.Request about keysPrefix to
// convert as etcdserverpb request
func parseKeyRequest(r *http.Request, clock clockwork.Clock) (etcdserverpb.Request, bool, error) {
var noValueOnSuccess bool
emptyReq := etcdserverpb.Request{}
err := r.ParseForm()
if err != nil {
return emptyReq, false, v2error.NewRequestError(
v2error.EcodeInvalidForm,
err.Error(),
)
}
// ...
var pIdx, wIdx uint64
if pIdx, err = getUint64(r.Form, "prevIndex"); err != nil {
return emptyReq, false, v2error.NewRequestError(
v2error.EcodeIndexNaN,
`invalid value for "prevIndex"`,
)
}
// ...
// Convert to etcdserverpb.Request proto request structure
rr := etcdserverpb.Request{
Method: r.Method,
Path: p,
Val: r.FormValue("value"),
Dir: dir,
PrevValue: pV,
PrevIndex: pIdx,
PrevExist: pe,
Wait: wait,
Since: wIdx,
Recursive: rec,
Sorted: sort,
Quorum: quorum,
Stream: stream,
}
// ...
return rr, noValueOnSuccess, nil
}
It is worth mentioning that etcd has officially used the v3 mode of communication by default after the v3.4 version, so we will focus on analyzing the v3 version of the code and describe it separately from the client and the server.
Client Side
The v3 client encapsulates a grpc connection for internal communication of the rpc service
// Client provides and manages an etcd v3 client session.
type Client struct {
Cluster
KV
Lease
Watcher
// rpc Connection
conn *grpc.ClientConn
cfg Config
//...
lg *zap.Logger
}
proto design
In the pkg of etcdserver, we can see some communication .proto files
../../etcd/etcdserver/etcdserverpb ((v3.4.0))
$ ls -l *.proto
-rw-r--r-- 1 Pixel_Pig 197121 1515 Oct 8 10:57 etcdserver.proto
-rw-r--r-- 1 Pixel_Pig 197121 2364 Oct 8 10:57 raft_internal.proto
-rw-r--r-- 1 Pixel_Pig 197121 35627 Oct 8 10:57 rpc.proto
which defines the services that etcd mainly provides external function modules
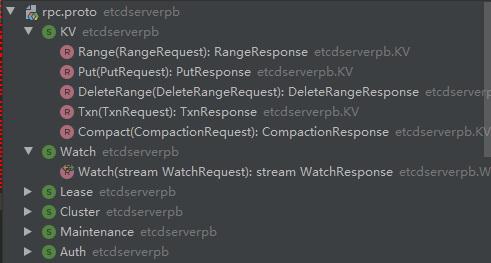
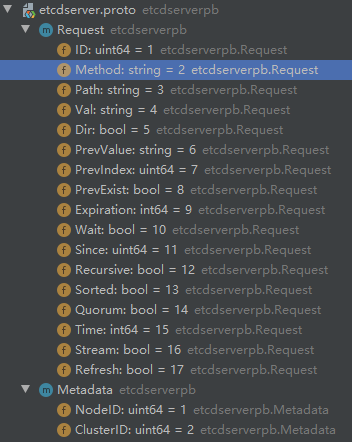
Request struct
This is the request body of etcd node rpc communication. The above v2 client version converts HttpRequest into etcdserverpb.Request is exactly from the etcdserver.proto file
KV Client
The client request will be called through the implementation of the KV interface kVClient, and the remote end is KVServer
func (c *kVClient) Range(ctx context.Context, in *RangeRequest, opts ...grpc.CallOption) (*RangeResponse, error) {
out := new(RangeResponse)
err := grpc.Invoke(ctx, "/etcdserverpb.KV/Range", in, out, c.cc, opts...)
if err != nil {
return nil, err
}
return out, nil
}
func (c *kVClient) Put(ctx context.Context, in *PutRequest, opts ...grpc.CallOption) (*PutResponse, error) {
out := new(PutResponse)
err := grpc.Invoke(ctx, "/etcdserverpb.KV/Put", in, out, c.cc, opts...)
if err != nil {
return nil, err
}
return out, nil
}
func (c *kVClient) DeleteRange(ctx context.Context, in *DeleteRangeRequest, opts ...grpc.CallOption) (*DeleteRangeResponse, error) {
out := new(DeleteRangeResponse)
err := grpc.Invoke(ctx, "/etcdserverpb.KV/DeleteRange", in, out, c.cc, opts...)
if err != nil {
return nil, err
}
return out, nil
}
Server Side
The components on the server side are more complex. Before sorting out the internal control communication, it is necessary to understand the role of each component.
The problem solved by the server is:
- Receive requests from clients and distribute to nodes
- Sensing cluster member changes and notifying members
- Synchronize or initiate recovery snapshots
Server Interceptor
We mentioned a KVServer in the previous client component. In fact, etcd also wraps a layer of interceptor for it, which is quotaKVServer
type quotaKVServer struct {
pb.KVServer
// Accessibility
qa quotaAlarmer
}
type quotaAlarmer struct {
q etcdserver.Quota
a Alarmer
id types.ID
}
func NewQuotaKVServer(s *etcdserver.EtcdServer) pb.KVServer {
return "aKVServer{
NewKVServer(s),
quotaAlarmer{etcdserver.NewBackendQuota(s, "kv"), s, s.ID()},
}
}
The role of this interceptor is to perform space detection on client requests, calculate the key-vaule resource consumption space for each request, and the server will count the remaining space as an alarm. If it exceeds, an error will be thrown:
ErrGRPCNoSpace = status.New(codes.ResourceExhausted, "etcdserver: mvcc: database space exceeded").Err()
If this happens to the cluster, the official documentation also gives suggestions:
fix mvcc: database space exceeded
- Historical version compression
- File defragmentation
Interface Relationship
In the language rules of go, use composition instead of inheritance, the interface of go is implicitly implemented, and the internal communication of raft nodes is mainly through the definition of channel members for messages Propagation, such as the conversion of external messages to the underlying log. The message body involving cross-machine nodes is sent by the http client.
The data flow diagram is as follows:
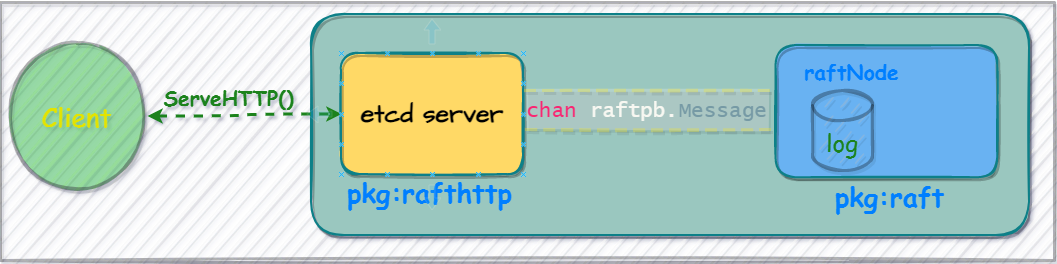
etcdserver In addition to exposing the API to the client, the logic for monitoring the communication of internal members is also registered at startup time. Next, let’s look at the internal logic of the server.
Communication Component: peer
The etcd cluster uses peer as a single-point structure for cross-network communication. Several core member functions are as follows, which internally encapsulate network requests between nodes, such as submitting snapshots to other nodes:
type Peer interface {
send(m raftpb.Message)
sendSnap(m snap.Message)
update(urls types.URLs)
}
Transporter Interface
The etcd cluster needs to maintain a peer node list. The method of etcd is to choose to extract one layer up, and use Transport to maintain the peer list, through Transport implements the Transporter interface to manage the peer members, and the Transporter interface mainly updates and maintains the peer members.
type Transporter interface {
// ...
AddRemote(id types.ID, urls []string)
AddPeer(id types.ID, urls []string)
RemovePeer(id types.ID)
RemoveAllPeers()
UpdatePeer(id types.ID, urls []string)
// ...
}
Transporter implement by Transport
type Transport struct {
//...
ID types.ID // local member ID
URLs types.URLs // local peer URLs
ClusterID types.ID // raft cluster ID for request validation
Raft Raft // raft state machine, to which the Transport forwards received messages and reports status
Snapshotter *snap.Snapshotter
// ...
streamRt http.RoundTripper // transmit small, frequent messages
pipelineRt http.RoundTripper // transmits large data with low frequency
mu sync.RWMutex // protect the remote and peer map
remotes map[types.ID]*remote // remotes map that helps newly joined member to catch up
peers map[types.ID]Peer // peers map
// Heartbeat detection
pipelineProber probing.Prober
streamProber probing.Prober
}
The overall main structural relationship is as follows:
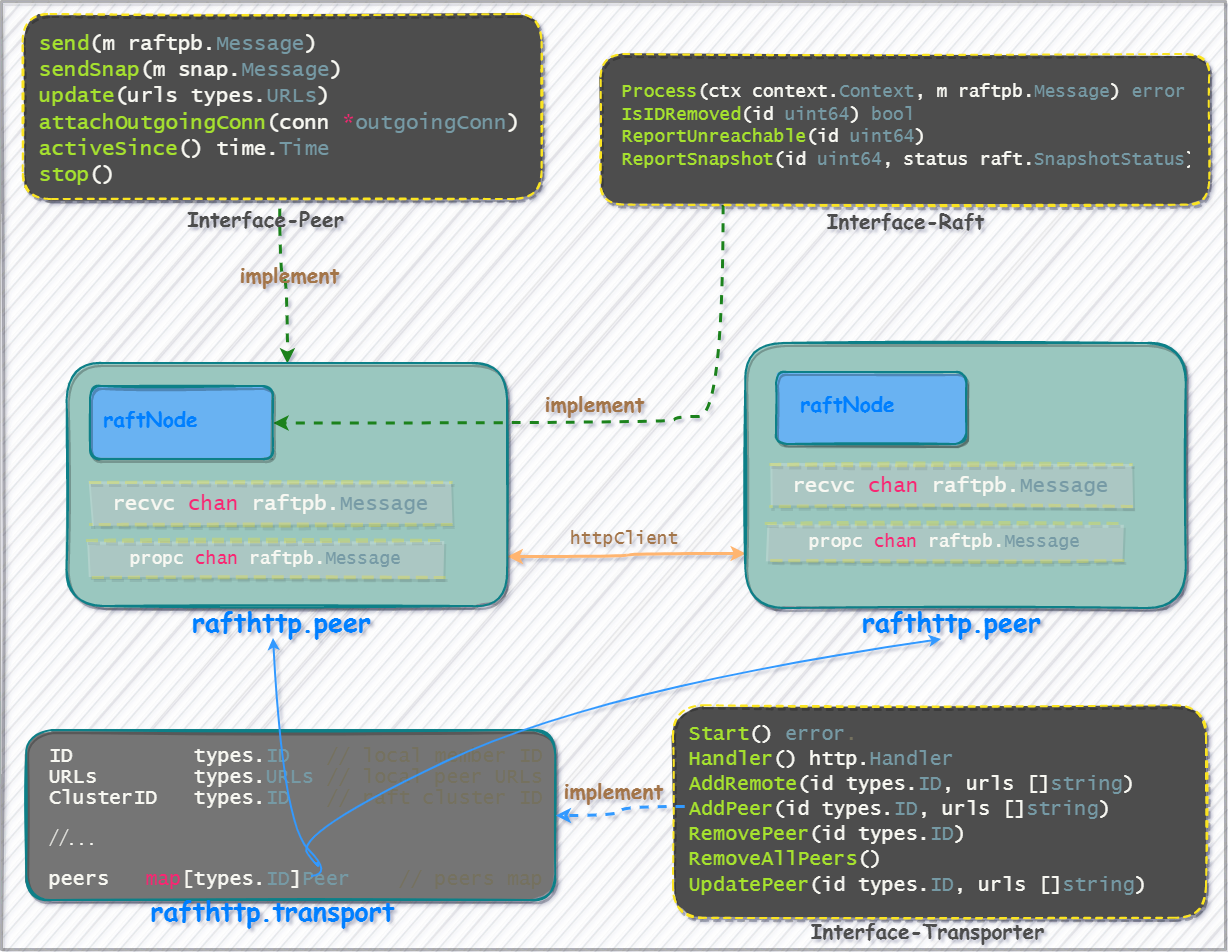 It can be seen that each
It can be seen that each peer structure has a raftNode node embedded in it, and the underlying log structure and file directory are connected through raftNode, such as MemoryStorage, wal, etc. The problem solved by the storage layer is to query and update the multi-version data of the log tree by returning the corresponding log subscript and combining with raft.
About the underlying storage will be expanded in the next part of this series :)
Here we mainly analyze transport, transport is registered in the Handler() function,
func (t *Transport) Handler() http.Handler {
pipelineHandler := newPipelineHandler(t, t.Raft, t.ClusterID)
streamHandler := newStreamHandler(t, t, t.Raft, t.ID, t.ClusterID)
snapHandler := newSnapshotHandler(t, t.Raft, t.Snapshotter, t.ClusterID)
mux := http.NewServeMux()
mux.Handle(RaftPrefix, pipelineHandler)
mux.Handle(RaftStreamPrefix+"/", streamHandler)
mux.Handle(RaftSnapshotPrefix, snapHandler)
mux.Handle(ProbingPrefix, probing.NewHandler())
return mux
}
Among them, several core functions are monitored
| Handler Implement | Method |
|---|---|
| pipelineHandler | Forward messages to internal raft nodes for processing |
| snapshotHandler | Transfer storage snapshots (short live link, big data), write to local db |
| streamHandler | Maintain long connection update heartbeat (tiny data) |
Part of the pipelineHandler processing logic is as follows:
func (h *pipelineHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
//...
// update to upsteam node
addRemoteFromRequest(h.tr, r)
limitedr := pioutil.NewLimitedBufferReader(r.Body, connReadLimitByte)
b, err := ioutil.ReadAll(limitedr)
if err != nil {
//...
}
// parse the message
var m raftpb.Message
if err := m.Unmarshal(b); err != nil {
// ...
return
}
receivedBytes.WithLabelValues(types.ID(m.From).String()).Add(float64(len(b)))
// forward to node inside for handling: node.step()
if err := h.r.Process(context.TODO(), m); err != nil {
switch v := err.(type) {
case writerToResponse:
v.WriteTo(w)
default:
// ...
}
return
}
// ...
}
Heartbeat Feedback
// server side
func (h *httpHealth) ServeHTTP(w http.ResponseWriter, r *http.Request) {
// return health
health := Health{OK: true, Now: time.Now()}
e := json.NewEncoder(w)
e.Encode(health)
}
Remember the Transport interface mentioned above, it is used to maintain raft member changes, and the AddPeer() and UpdatePeer() sub-functions will create a new protocol.
The process performs periodic heartbeat detection on the cluster list:
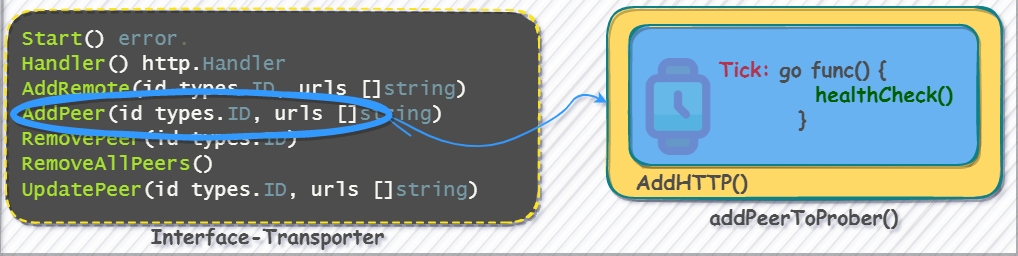
func (p *prober) AddHTTP(id string, probingInterval time.Duration, endpoints []string) error {
p.mu.Lock()
defer p.mu.Unlock()
// ...
go func() {
pinned := 0
for {
select {
case <-ticker.C:
start := time.Now()
req, err := http.NewRequest("GET", endpoints[pinned], nil)
// ...
resp, err := p.tr.RoundTrip(req)
// ...
if err != nil {
s.recordFailure(err)
pinned = (pinned + 1) % len(endpoints)
continue
}
var hh Health
d := json.NewDecoder(resp.Body)
err = d.Decode(&hh)
resp.Body.Close()
if err != nil || !hh.OK {
s.recordFailure(err)
pinned = (pinned + 1) % len(endpoints)
continue
}
s.record(time.Since(start), hh.Now)
case <-s.stopC:
ticker.Stop()
return
}
}
}()
return nil
}
Summary
The above is etcd’s implementation of the functions of each module. etcd implements the implementation module layer by layer from the network layer - raft state - log storage layer through layered architecture design.
If you are interested, you can choose to cut in from a certain level of code follow the drawing above. The next article will talk about the underlying storage of etcd:)
Reference link
- 《HTTP/2 in Action》
- etcd文档
https://etcd.io/docs/v3.5/learning/ - etc技术内幕 - 百里燊
- 云原生分布式存储基石etcd深入解析 - 华为云