
聊一聊网络编程TCP流的组包拆包
众所周知,包体传输是网络通信中不可或缺的一部分,无论是应用层HTTP包的header或者body,还是传输层TCP的流式数据,都是对数据的分组与拆解。
前言
今天来聊一聊网络通信中包体传输的话题,本文将从几个实际应用的例子来比对网络编程中常见的包体解析方式。
概念
在进入话题之前,我们先来梳理网络中TCP连接的相关概念,网络连接中的包,就像河流中一个又一个的船。

TCP连接
网络连接的建立,一个TCP的连接是由四元组组成,即源IP+源端口 <-> 目标ip+目标端口 ,底层是由文件句柄也称为fd组成,因此在不考虑连接复用的情况下,单机连接数会受到可用文件句柄数量的限制。
传输格式
在建立完连接之后,服务端与客户端各自会对该连接进行一发一收,既然涉及到交互那么必然要约定一个传输格式,比如AB两个国家约定通信的语言格式,是统一用哪国语言,语句采用何种顺序,如主语-谓语-宾语等。
序列化
约定完传输格式之后,数据在网络中传输还需要进行加工,因为计算机更喜欢二进制字节流,所以就是我们常说的序列化,序列化之后的信息相当于对其进行了压缩,节省了网络带宽。
关于序列化有一个经常讨论到的就是大端与小端,指的是传输时候先传高位字节地址,还是先传低位字节地址。
在Go中有相应的API可以进行指定二进制编/解码:
// 小端:字节顺序以低位地址开始
var LittleEndian littleEndian
// 大端:字节顺序以高位地址开始
var BigEndian bigEndian
Write(buf, LittleEndian, &b1)
Read(buf, LittleEndian, &p)
关于二进制大端小端的序列化方式,从下面几个Go开源项目可以看到示例:
BigCache 本地缓存序列化
func wrapEntry(timestamp uint64, hash uint64, key string, entry []byte, buffer *[]byte) []byte {
keyLength := len(key)
blobLength := len(entry) + headersSizeInBytes + keyLength
// ...
binary.LittleEndian.PutUint64(blob, timestamp)
binary.LittleEndian.PutUint64(blob[timestampSizeInBytes:], hash)
binary.LittleEndian.PutUint16(blob[timestampSizeInBytes+hashSizeInBytes:], uint16(keyLength))
copy(blob[headersSizeInBytes:], key)
copy(blob[headersSizeInBytes+keyLength:], entry)
return blob[:blobLength]
}
Grpc 标记字节流中的帧报文
// MakeFrame creates a handshake frame.
func MakeFrame(pl string) []byte {
f := make([]byte, len(pl)+conn.MsgLenFieldSize)
binary.LittleEndian.PutUint32(f, uint32(len(pl)))
copy(f[conn.MsgLenFieldSize:], []byte(pl))
return f
}
拆包、粘包
无论是以大端还是小端的方式,从序列化的字节流经过反序列化得到的信息,也叫报文,下一步就是对报文进行语义解析了。
我们都知道在TCP流中,数据包是有序的,但是在一管道数据中,应用层怎么知道数据的开始和结束呢,即如何区分其中某一段数据是归属上一个请求,还是下一个请求,这就是常说的拆包粘包了。一般有两种解法:
一、约定特殊分隔符
我们来看下有哪些使用场景,最常见的案例比如像HTTP,我们看它是怎么约定的:
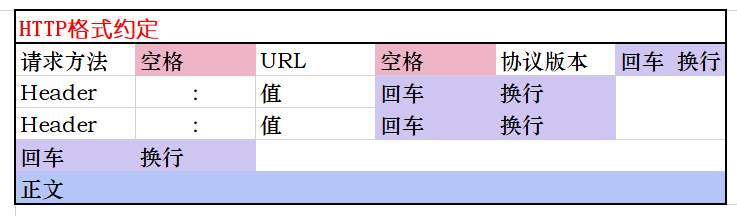 以
以回车换行作为分割符,
- 通过空格区分请求方法、URL和协议
- 通过
:作为键值对标识 - 如果没有找到
:,则说明头部解析结束,下一个回车换行之后就是正文。
我们模拟一个HTTP请求,并通过WireShark软件抓包分析一下,得到原文如下:
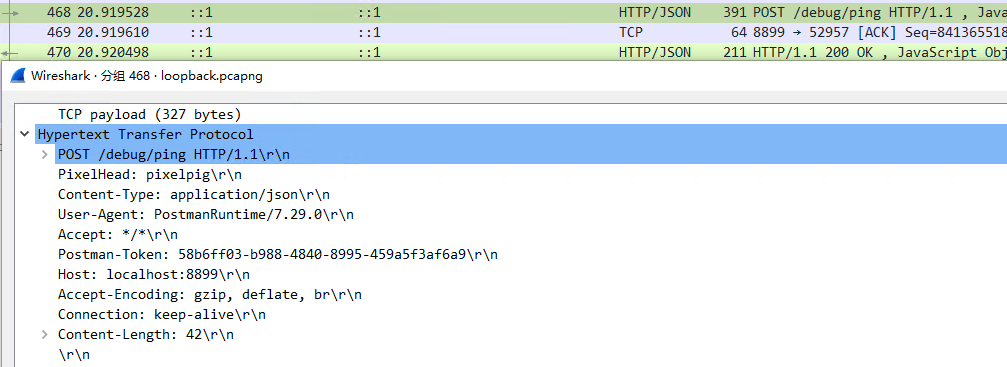 可以看到以
可以看到以\r\n作为分隔符,其切分规则是符合协议标准的。(注:因为这是标准的HTTP协议而不是HTTPS,没有进行加密,所以传输的报文是明文显示)
还有一个典型的例子也比较常用,就是Redis协议,我们来看下Redis是怎么约定的:
参考RESP官方协议,Redis同样也是使用\r\n作为分隔符,每个Redis命令都有相应的前缀字符进行匹配,基本涵盖了我们使用Redis API的日常需求。
- For Simple Strings, the first byte of the reply is “+”
- For Errors, the first byte of the reply is “-”
- For Integers, the first byte of the reply is “:”
- For Bulk Strings, the first byte of the reply is “$”
- For Arrays, the first byte of the reply is “*",数组以
*开始,后面数字表示多少个组
Redigo驱动包
我们来看一下Redis在Go驱动中是怎么解析的,以下代码引用自go-redis驱动
const (
// 约定前缀符号
ErrorReply = '-' // 错误
StatusReply = '+' // 简单类型,如"+OK\r\n"
IntReply = ':' // 整数类型
StringReply = '$' // 字符串类型
ArrayReply = '*' // 数组类型,后面数字代表带上多少组
)
//...
func (r *Reader) ReadReply(m MultiBulkParse) (interface{}, error) {
line, err := r.ReadLine()
if err != nil {
return nil, err
}
switch line[0] {
case ErrorReply:
return nil, ParseErrorReply(line)
case StatusReply:
return string(line[1:]), nil
case IntReply:
return util.ParseInt(line[1:], 10, 64)
case StringReply:
return r.readStringReply(line)
case ArrayReply:
n, err := parseArrayLen(line)
if err != nil {
return nil, err
}
if m == nil {
err := fmt.Errorf("redis: got %.100q, but multi bulk parser is nil", line)
return nil, err
}
return m(r, n)
}
return nil, fmt.Errorf("redis: can't parse %.100q", line)
}
根据单元测试案例,Redis命令经过报文协议转换,在Go里面格式如下:
var writeTests = []struct {
args []interface{}
expected string
}{
{
[]interface{}{"SET", "key", "value"},
"*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n",
},
{
[]interface{}{"SET", "key", "value"},
"*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n",
},
{
[]interface{}{"SET", "key", int64(math.MinInt64)},
"*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$20\r\n-9223372036854775808\r\n",
},
{
[]interface{}{"SET", "key", durationArg{time.Minute}},
"*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$2\r\n60\r\n",
},
{
[]interface{}{"SET", "key", recursiveArg(123)},
"*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$3\r\n123\r\n",
},
{
[]interface{}{"ECHO", true, false},
"*3\r\n$4\r\nECHO\r\n$1\r\n1\r\n$1\r\n0\r\n",
},
}
以上就是通过特殊分隔符进行报文还原的案例,接下来我们看下另一种常见解法。
二、约定固定区间规则,再根据长度读取
这种称为TLV(type-lenth-value),类型-长度-值。顾名思义就是首位约定类型,第二位约定要读取的长度,根据长度获取结束下标。
有的时候type和lenth可以合成一个,比如说约定type=1时候lenth为3,type=2时候lenth为5等等,可以根据服务端客户端双方约定,协议如下图:

之前参考了go实现的轻量级tcp服务器zinx框架,其中就有网络通信中包体的封装与拆解,这个框架约定的协议就是TLV的方式,我们来看下它的实现细节:
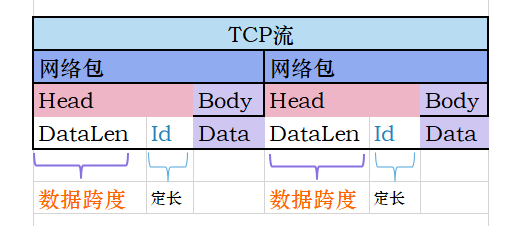
在TCP流中,每个网络包分为Head和Body,每个Head又定义了这个包的数据跨度和业务Id,应用层在读取的时候根据包的数据跨度就能知道Body的结束下标,从而读取相应Data 的区间了。
代码示例:
//约定Message 消息体结构
type Message struct {
DataLen uint32 //消息的长度
ID uint32 //消息的ID
Data []byte //消息的内容
}
//NewMsgPackage 创建一个Message消息包
func NewMsgPackage(ID uint32, data []byte) *Message {
return &Message{
DataLen: uint32(len(data)),
ID: ID,
Data: data,
}
}
//Pack 封包方法(压缩数据)
func (dp *DataPack) Pack(msg ziface.IMessage) ([]byte, error) {
//创建一个存放bytes字节的缓冲
dataBuff := bytes.NewBuffer([]byte{})
//1. 写dataLen
if err := binary.Write(dataBuff, binary.LittleEndian, msg.GetDataLen()); err != nil {
return nil, err
}
//2. 写msgID
if err := binary.Write(dataBuff, binary.LittleEndian, msg.GetMsgID()); err != nil {
return nil, err
}
//3. 写data数据
if err := binary.Write(dataBuff, binary.LittleEndian, msg.GetData()); err != nil {
return nil, err
}
return dataBuff.Bytes(), nil
}
上面是对消息的封装,下面来看下怎么在读取方拆解的:
// Header定长跨度
var defaultHeaderLen uint32 = 8
//GetHeadLen 获取包头长度方法
func (dp *DataPack) GetHeadLen() uint32 {
//ID uint32(4字节) + DataLen uint32(4字节)
return defaultHeaderLen
}
//处理客户端请求
go func(conn net.Conn) {
//创建封包拆包对象dp
dp := NewDataPack()
for {
//1 先读出流中的head部分
headData := make([]byte, dp.GetHeadLen())
_, err := io.ReadFull(conn, headData) //ReadFull 会把msg填充满为止
if err != nil {
fmt.Println("read head error")
}
//将headData字节流 拆包到msg中
msgHead, err := dp.Unpack(headData)
if err != nil {
fmt.Println("server unpack err:", err)
return
}
// Header跨度大于0,有数据才读
if msgHead.GetDataLen() > 0 {
msg := msgHead.(*Message)
msg.Data = make([]byte, msg.GetDataLen())
//根据dataLen从io中读取字节流
_, err := io.ReadFull(conn, msg.Data)
if err != nil {
fmt.Println("server unpack data err:", err)
return
}
}
}
}(conn)
参考资料
RESP协议:
Zinx TCP通信框架