
聊一聊etcd系列之三:节点通信协议
etcd在微服务领域使用场景十分普遍,经常用于作为一个注册中心,提供服务注册与发现。近期梳理了etcd的一些内部结构与依赖组件,今天来聊一聊etcd的节点通信协议。

前言
etcd在微服务领域使用场景十分普遍,经常用于作为一个注册中心,提供服务注册与发现常见的比如K8S框架就以etcd作为基础组件进行内部交互。前面提到etcd通过分层对各个模块进行实现,今天我们来进入网络部分,本篇将聊一聊etcd如何对外提供的API,从客户端和服务端来逐步分析。
它解决了什么问题
通信效率
聊到通信协议固然要考虑的是节点间的通信方式,早期的etcd通信版本是v2,通过HTTP+JSON暴露外部API,由于经常需要服务感知节点配置变动或者监听推送,客户端和服务端需要频繁通信,早期的v2采用HTTP1.1的长连接来维持,经过如此通信效率依然不高。
由于这篇集中讲网络通信,所以关于v2到v3的升级特性只关注网络通信相关的功能,其他存储特性优化将在后续“底层存储”进行分析,比如v3的MVCC、快照、事务等。
HTTP/1.X VS HTTP/2
我们先来简单聊一聊HTTP/1.x到HTTP/2的演变:
连接数
在HTTP/2之前,HTTP/1并不高效,因为同一个请求等待响应时候会阻塞后续网络包的发送,当今网络的大部分问题已经由带宽变成延迟问题,有时候提高带宽(发送内容大小)的收益已经不如降低延迟(网络传输耗时)性价比来的高。
此外,我们也不能暴力的开启多连接,毕竟基于三次握手创建连接是要消耗资源的,此外单连接的阻塞问题并没有得到解决,试图开启多连接来优化是治标不治本的。
文本协议
HTTP/1采用文本协议,其编码格式对人类友好,但是传输并不高效,尚且不论安全问题(HTTPS)。
etcd v3版本引进了grpc+protobuf的通信方式(基于HTTP/2.0),其优势在于:
- 采用二进制压缩传输,序列/反序列化更加高效
- 基于HTTP2.0的服务端主动推送特性,对事件多路复用做了优化
Watch功能使用grpc的stream流进行感知,同一个客户端和服务端采用单一连接,替代v2的HTTP长轮询检测,直接减少连接数和内存开销
兼容性
etcd v3版本为了向上兼容v2 API版本,提供了grpc网关来支持原HTTP JSON接口支持。
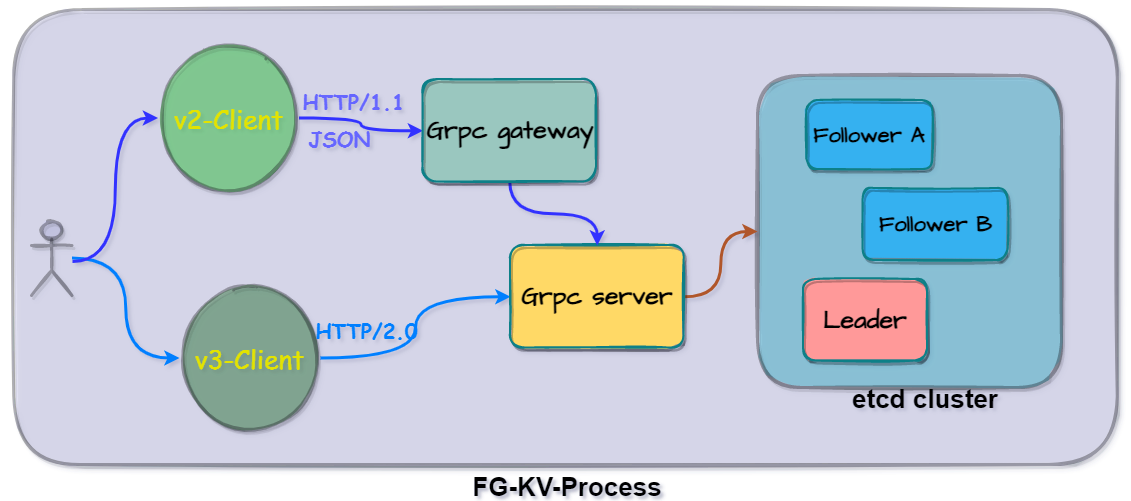
它是如何解决的
我们在这个系列的第一篇讲到etcd通过分层把各个模块功能进行拆分,分别进行实现,提高代码的可读性和降低维护成本。
在通信模块这一块,etcd同样采用了分层策略,其中外部跨机器节点的网络模块集中在api.rafthttp的package,而节点状态更新和底层存储的分布在etcd.raft的package。
v2协议转换
这是一段etcd v2请求过渡到底层etcdserver的转换逻辑:
// parseKeyRequest 将接收到的关于 keysPrefix 的 http.Request 转换为
// 转换为etcdserverpb请求
func parseKeyRequest(r *http.Request, clock clockwork.Clock) (etcdserverpb.Request, bool, error) {
var noValueOnSuccess bool
emptyReq := etcdserverpb.Request{}
err := r.ParseForm()
if err != nil {
return emptyReq, false, v2error.NewRequestError(
v2error.EcodeInvalidForm,
err.Error(),
)
}
// ...
var pIdx, wIdx uint64
if pIdx, err = getUint64(r.Form, "prevIndex"); err != nil {
return emptyReq, false, v2error.NewRequestError(
v2error.EcodeIndexNaN,
`invalid value for "prevIndex"`,
)
}
// ...
// 转换为etcdserverpb.Request proto 请求结构
rr := etcdserverpb.Request{
Method: r.Method,
Path: p,
Val: r.FormValue("value"),
Dir: dir,
PrevValue: pV,
PrevIndex: pIdx,
PrevExist: pe,
Wait: wait,
Since: wIdx,
Recursive: rec,
Sorted: sort,
Quorum: quorum,
Stream: stream,
}
// ...
return rr, noValueOnSuccess, nil
}
值得一提的是,etcd官方已经在v3.4版本之后全局默认使用v3方式通信了,所以后续我们着重分析v3版本的代码,分别从客户端和服务端来分开描述。
客户端
v3客户端封装了一个grpc连接,用于rpc服务内部通信
// Client provides and manages an etcd v3 client session.
type Client struct {
Cluster
KV
Lease
Watcher
// rpc Connection
conn *grpc.ClientConn
cfg Config
//...
lg *zap.Logger
}
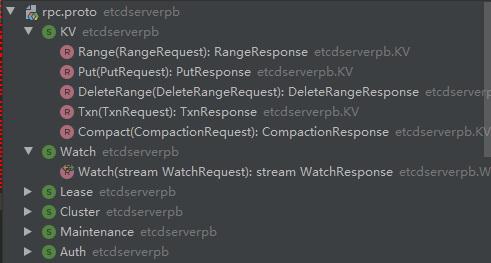
proto协议文件
在etcdserver的pkg中,约定了一些通信的.proto文件
../../etcd/etcdserver/etcdserverpb ((v3.4.0))
$ ls -l *.proto
-rw-r--r-- 1 Pixel_Pig 197121 1515 Oct 8 10:57 etcdserver.proto
-rw-r--r-- 1 Pixel_Pig 197121 2364 Oct 8 10:57 raft_internal.proto
-rw-r--r-- 1 Pixel_Pig 197121 35627 Oct 8 10:57 rpc.proto
定义了etcd主要对外提供功能模块的服务
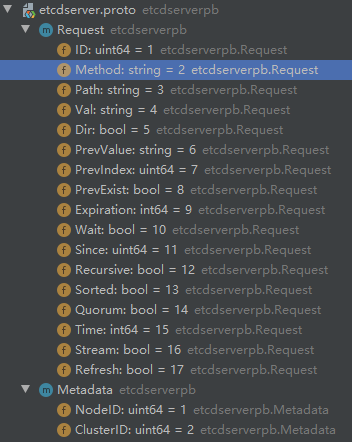
Request请求结构
这是etcd节点rpc通信的请求体,上面v2客户端版本把HttpRequest转换成的etcdserverpb.Request正是来自于etcdserver.proto文件
kv客户端
客户端请求会经过KV接口的实现kVClient进行调用,远程端是KVServer
func (c *kVClient) Range(ctx context.Context, in *RangeRequest, opts ...grpc.CallOption) (*RangeResponse, error) {
out := new(RangeResponse)
err := grpc.Invoke(ctx, "/etcdserverpb.KV/Range", in, out, c.cc, opts...)
if err != nil {
return nil, err
}
return out, nil
}
func (c *kVClient) Put(ctx context.Context, in *PutRequest, opts ...grpc.CallOption) (*PutResponse, error) {
out := new(PutResponse)
err := grpc.Invoke(ctx, "/etcdserverpb.KV/Put", in, out, c.cc, opts...)
if err != nil {
return nil, err
}
return out, nil
}
func (c *kVClient) DeleteRange(ctx context.Context, in *DeleteRangeRequest, opts ...grpc.CallOption) (*DeleteRangeResponse, error) {
out := new(DeleteRangeResponse)
err := grpc.Invoke(ctx, "/etcdserverpb.KV/DeleteRange", in, out, c.cc, opts...)
if err != nil {
return nil, err
}
return out, nil
}
服务端
服务端的组件较为复杂,在梳理内部控件通信之前,有必要先了解各个组件充当的角色是什么。 服务端解决的问题是:
- 接收客户端的请求并对节点进行分发
- 感知集群成员变动,对成员通知
- 同步或者启动恢复快照
服务端拦截器
我们在前面客户端组件提到一个KVServer,其实etcd还对其包了一层拦截器,就是quotaKVServer
type quotaKVServer struct {
pb.KVServer
// 辅助功能
qa quotaAlarmer
}
type quotaAlarmer struct {
q etcdserver.Quota
a Alarmer
id types.ID
}
func NewQuotaKVServer(s *etcdserver.EtcdServer) pb.KVServer {
return "aKVServer{
NewKVServer(s),
quotaAlarmer{etcdserver.NewBackendQuota(s, "kv"), s, s.ID()},
}
}
这个拦截器的作用是对客户端请求进行空间检测,对每个请求计算Key-Vaule资源消耗空间,服务端统计剩余空间以此来做告警,如果超过则抛出错误:
ErrGRPCNoSpace = status.New(codes.ResourceExhausted, "etcdserver: mvcc: database space exceeded").Err()
如果集群出现这种情况,官方文档也给出了建议:
fix mvcc: database space exceeded
- 历史版本压缩
- 文件碎片整理
接口关系
在go的语言规则中,使用组合替代继承,go的接口采用隐式实现,raft节点内部通信主要是通过定义channel成员进行消息传播,比如外部消息到底层log的转换。而涉及跨机器节点的消息体则使用http客户端发送,其数据流图如下:
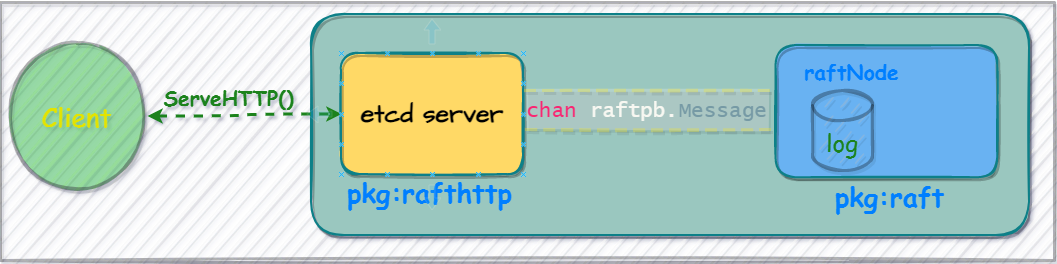
etcdserver除了对客户端暴露API使用之外,在启动时刻还注册监听了内部成员通信的一下逻辑,接下来我们看下server端内部逻辑。
peer-通信组件
etcd集群使用peer作为单点结构来做跨网络通信,几个核心的成员函数如下,内部封装了节点间的网络请求,比如提交快照给其他节点:
type Peer interface {
send(m raftpb.Message)
sendSnap(m snap.Message)
update(urls types.URLs)
}
Transporter接口
etcd集群则需要维护一个peer节点列表,etcd的做法是选择往上抽取一层,使用Transport来维护peer列表,通过Transport实现了Transporter接口来对peer成员进行管理,Transporter接口主要是对peer成员进行更新维护。
type Transporter interface {
// ...
AddRemote(id types.ID, urls []string)
AddPeer(id types.ID, urls []string)
RemovePeer(id types.ID)
RemoveAllPeers()
UpdatePeer(id types.ID, urls []string)
// ...
}
Transporter的实现体Transport
type Transport struct {
//...
ID types.ID // local member ID
URLs types.URLs // local peer URLs
ClusterID types.ID // raft cluster ID for request validation
Raft Raft // raft state machine, to which the Transport forwards received messages and reports status
Snapshotter *snap.Snapshotter
// ...
streamRt http.RoundTripper // 传输小数据量、频繁的消息
pipelineRt http.RoundTripper // 传输数据量大、频率低的逻辑
mu sync.RWMutex // protect the remote and peer map
remotes map[types.ID]*remote // remotes map that helps newly joined member to catch up
peers map[types.ID]Peer // peers map
// 心跳探测
pipelineProber probing.Prober
streamProber probing.Prober
}
整体主要结构关系如下图:
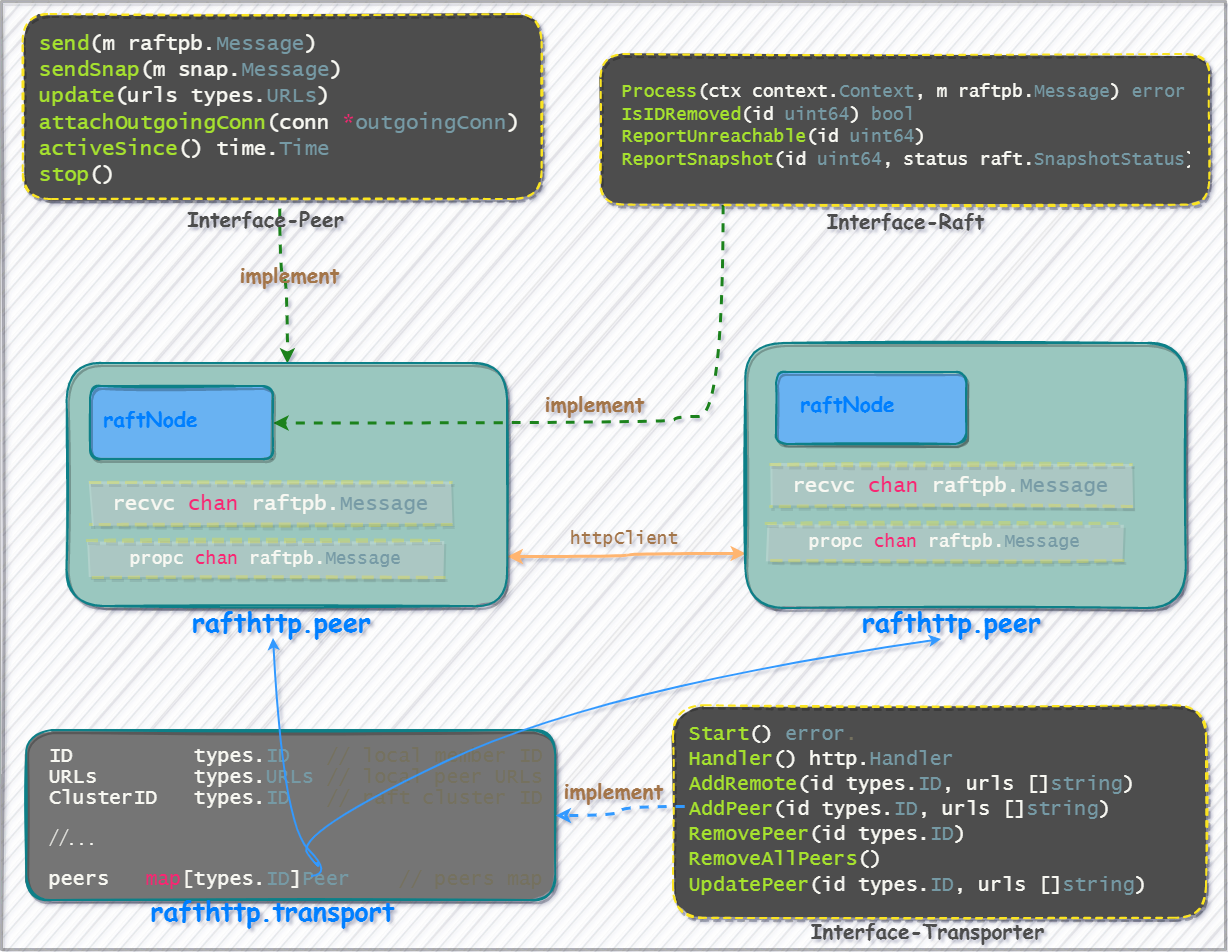 可以看到,每个
可以看到,每个peer结构又内嵌了raftNode节点,通过raftNode连接了底层的日志结构、文件目录,如MemoryStorage,wal等,存储层解决的问题是通过返回相应的日志下标,结合raft对日志树多版本数据进行查询、更新。
关于底层存储将在本系列下一篇展开:)
这里我们主要分析transport,transport在Handler()函数进行统一注册,
func (t *Transport) Handler() http.Handler {
pipelineHandler := newPipelineHandler(t, t.Raft, t.ClusterID)
streamHandler := newStreamHandler(t, t, t.Raft, t.ID, t.ClusterID)
snapHandler := newSnapshotHandler(t, t.Raft, t.Snapshotter, t.ClusterID)
mux := http.NewServeMux()
mux.Handle(RaftPrefix, pipelineHandler)
mux.Handle(RaftStreamPrefix+"/", streamHandler)
mux.Handle(RaftSnapshotPrefix, snapHandler)
mux.Handle(ProbingPrefix, probing.NewHandler())
return mux
}
其中对几个核心功能进行监听
| Handler实现 | 功能模块 |
|---|---|
| pipelineHandler | 转发消息到内部raft节点进行处理 |
| snapshotHandler | 传输存储快照(短链接、大数据),写入本地db |
| streamHandler | 维护长连接更新心跳(小数据) |
部分pipelineHandler处理逻辑如下:
func (h *pipelineHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
//...
// 更新上游转发节点
addRemoteFromRequest(h.tr, r)
limitedr := pioutil.NewLimitedBufferReader(r.Body, connReadLimitByte)
b, err := ioutil.ReadAll(limitedr)
if err != nil {
//...
}
// 解析消息体
var m raftpb.Message
if err := m.Unmarshal(b); err != nil {
// ...
return
}
receivedBytes.WithLabelValues(types.ID(m.From).String()).Add(float64(len(b)))
// 转发至底层node进行处理,即node.step()
if err := h.r.Process(context.TODO(), m); err != nil {
switch v := err.(type) {
case writerToResponse:
v.WriteTo(w)
default:
// ...
}
return
}
// ...
}
心跳反馈
// server side
func (h *httpHealth) ServeHTTP(w http.ResponseWriter, r *http.Request) {
// return health
health := Health{OK: true, Now: time.Now()}
e := json.NewEncoder(w)
e.Encode(health)
}
还记得上面提到的Transport接口吗,它用于维护raft成员变动,在AddPeer()和UpdatePeer()子函数都会新创建协程对集群列表做定期心跳检测
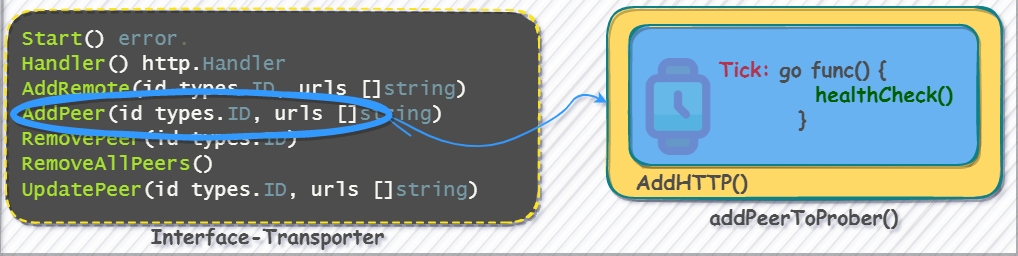
func (p *prober) AddHTTP(id string, probingInterval time.Duration, endpoints []string) error {
p.mu.Lock()
defer p.mu.Unlock()
// ...
go func() {
pinned := 0
for {
select {
case <-ticker.C:
start := time.Now()
req, err := http.NewRequest("GET", endpoints[pinned], nil)
// ...
resp, err := p.tr.RoundTrip(req)
// ...
if err != nil {
s.recordFailure(err)
pinned = (pinned + 1) % len(endpoints)
continue
}
var hh Health
d := json.NewDecoder(resp.Body)
err = d.Decode(&hh)
resp.Body.Close()
if err != nil || !hh.OK {
s.recordFailure(err)
pinned = (pinned + 1) % len(endpoints)
continue
}
s.record(time.Since(start), hh.Now)
case <-s.stopC:
ticker.Stop()
return
}
}
}()
return nil
}
总结
以上是etcd对各个模块功能的实现,etcd通过分层架构设计,把实现模块从网络层-raft状态-日志存储层逐层实现,读者感兴趣可以选择从某个层级代码进行切入,本系列的下一篇将聊一聊etcd的底层存储。
参考链接
- 《HTTP/2 in Action》
- etcd文档
https://etcd.io/docs/v3.5/learning/ - etc技术内幕 - 百里燊
- 云原生分布式存储基石etcd深入解析 - 华为云