
聊一聊etcd系列之二:raft一致性协议
共识算法旨在机器集群出现异常时候能够维持一个一致认可的结论来保证对外提供服务,今天来聊一聊etcd的共识机制—-raft协议。

解决什么问题
在进入etcd的raft之前,我们先来聊聊分布式系统的一致性是什么,raft协议解决了什么问题。
一致性的不同语义
实际上,在ACID事务特性中,一致性C更像是一种能量守恒或者质量守恒,比如转账、抢购,金额物品不会凭空消失或者出现冗余。
在分布式领域,分布式一致性更多往往指的是共识,指的是多个节点达成一致意见(要么大家一块错,要么一块对),区别在如果是ACID事务语义下的一致性,一般指强一致性。
如何解决
etcd内部通过选举和记录同步来达到一致性, etcd把更新记录通知到各个节点,在半数以上节点获得ack之后,主节点提交并且通知其他节点一同提交达成一致数据同步。此外,etcd日志会对每一个认可的操作进行记录和定期压缩归档。
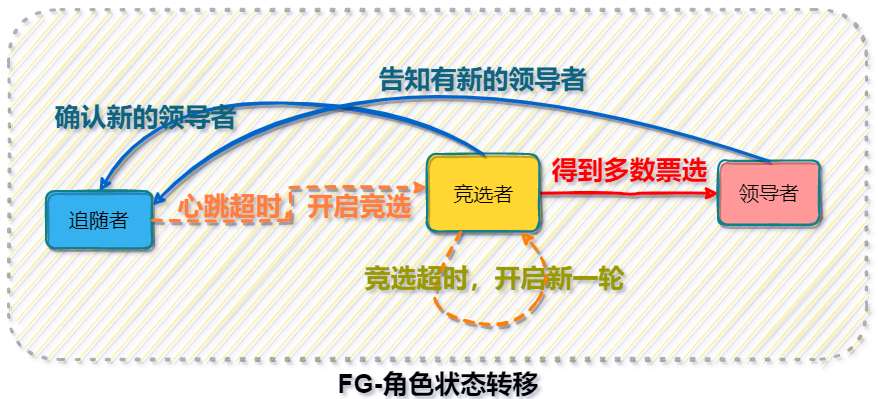
选举与状态转移
在raft协议中,每个节点有三个角色状态,分别是:领导者Leader、竞选者Candidate、追随者Follower。节点通过定期的心跳探测和记录同步来更新各个节点的状态,每个节点都有争当Leader的意识,Leader通过与Follower定期发送心跳,来告知任期未结束,当心跳超时或者出现网络分区,Follower则会参与竞选,但是要遵循一些规则:
- Leader必须由Candidate产生,且得到了大多数票数
- 在已有Leader且当前Leader的任期是最新的,Follower不参与竞选
- 在Leader心跳超时的情况,Follower参与竞选变成Candidate,并为自己记一次投票
- 如果节点的日志比Candidate候选人的日志更新时间大,就会拒绝候选人的投票请求
三个角色的状态转换如下图[FG-角色状态转移]所示:
日志副本
我们知道,etcd的分布式存储功能必定要涉及到数据多份存储版本的概念,etcd各个节点的数据版本是怎么同步的呢?
etcd使用日志来记录数据,每个节点都有自己的本地日志,这些日志来自Leader的同步,记录当时Leader的任期编号,简称为termId,这个任期编号用来区分日志文件的版本新旧。即如果节点的日志比Candidate候选人的日志更新时间大,就会拒绝候选人的投票请求。
一旦新的Leader角色上任,Leader会通过向Follower同步当前自己可提交的日志下标,如果有Follower没有跟上,Leader会逐级发送上一次的日志下标给Follower,最终直到Follower追上对齐同步。
各个角色的日志数据格式如下,t代表任期编号,kv是键值对。
Leader和Follower通过MatchIndex和NextIndex来交互,Follower会告知Leader当前已收到的最大匹配下标MatchIndex,Leader则通过NextIndex来同步给Follower最新节点。
各节点日志示意图如下:
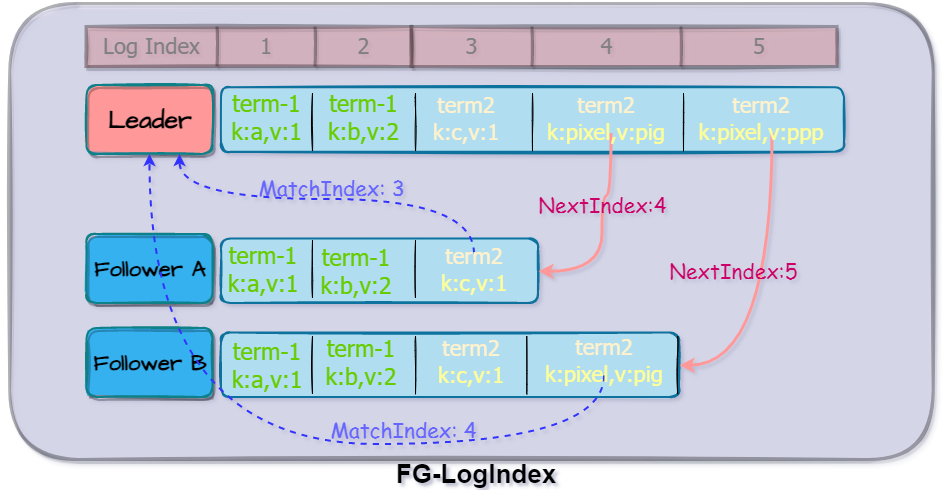
通过MatchIndex,Leader节点能够知道当前集群已被大多数节点认可的记录,则可以通过广播Msg告知其他Follower一块提交。
同步请求体结构如下:
type Entry struct {
// 任期id
Term uint64 `protobuf:"varint,2,opt,name=Term" json:"Term"`
// 日志下标
Index uint64 `protobuf:"varint,3,opt,name=Index" json:"Index"`
Type EntryType `protobuf:"varint,1,opt,name=Type,enum=raftpb.EntryType" json:"Type"`
Data []byte `protobuf:"bytes,4,opt,name=Data" json:"Data,omitempty"`
}
// AppendEntries RPC请求:尝试同步记录给节点
func (r *raft) appendEntry(es ...pb.Entry) (accepted bool) {
li := r.raftLog.lastIndex()
for i := range es {
es[i].Term = r.Term
es[i].Index = li + 1 + uint64(i)
}
// Track the size of this uncommitted proposal.
if !r.increaseUncommittedSize(es) {
// 当前记录日志没有跟上Leader
r.logger.Debugf(
"%x appending new entries to log would exceed uncommitted entry size limit; dropping proposal",
r.id,
)
// 拒绝Leader的新记录,需要获得旧记录来对齐
return false
}
// use latest "last" index after truncate/append
li = r.raftLog.append(es...)
r.prs.Progress[r.id].MaybeUpdate(li)
// Regardless of maybeCommit's return, our caller will call bcastAppend.
r.maybeCommit()
return true
}
日志压缩
由于操作更新日志的增量追加,raft节点在达成一致之后,会对日志版本进行定期归档压缩,有点类似于Redis的AOF和Snapshot备份策略,一次压缩可以释放空间,减轻存储空间避免对大量操作日志进行重放,也方便落后太多日志的节点快速赶上Leader。
其中,raft启动会有个关联成员storage用来存储日志数据集合,具体相关操作是在etcd的raft.Storage接口实现的。核心的成员如下
type bootstrappedRaft struct {
lg *zap.Logger
heartbeat time.Duration
peers []raft.Peer
config *raft.Config
// raft server启动关联存储实现类
storage *raft.MemoryStorage
}
//...
//Storage接口实现类MemoryStorage
type MemoryStorage struct {
sync.Mutex
hardState pb.HardState
snapshot pb.Snapshot
// ents存放当前节点操作集合,每个Entry表示日志附加属性
ents []pb.Entry
}
//Entry附加属性
type Entry struct {
Term uint64 `protobuf:"varint,2,opt,name=Term" json:"Term"`
Index uint64 `protobuf:"varint,3,opt,name=Index" json:"Index"`
Type EntryType `protobuf:"varint,1,opt,name=Type,enum=raftpb.EntryType" json:"Type"`
Data []byte `protobuf:"bytes,4,opt,name=Data" json:"Data,omitempty"`
}
raft会定期创建快照来对日志进行压缩,相当于保存快照到本地文件,之后执行Compact()函数对ents字段进行轮转,保留新一轮的下标。
// Compact discards all log entries prior to compactIndex.
// It is the application's responsibility to not attempt to compact an index
// greater than raftLog.applied.
func (ms *MemoryStorage) Compact(compactIndex uint64) error {
ms.Lock()
defer ms.Unlock()
offset := ms.ents[0].Index
if compactIndex <= offset {
return ErrCompacted
}
if compactIndex > ms.lastIndex() {
getLogger().Panicf("compact %d is out of bound lastindex(%d)", compactIndex, ms.lastIndex())
}
i := compactIndex - offset
ents := make([]pb.Entry, 1, 1+uint64(len(ms.ents))-i)
ents[0].Index = ms.ents[i].Index
ents[0].Term = ms.ents[i].Term
ents = append(ents, ms.ents[i+1:]...)
ms.ents = ents
return nil
}
其实,在MemoryStorage提交之前,节点还会先写到本地磁盘持久化,一旦故障拉起可以重建数据,这个过程叫做WAL预写日志。
关于日志存储更多细节,将在本系列的 etcd存储分析 展开聊。
网络分区处理
我们知道网络节点故障其实是会发生的,这里我们分为两种情况来分析如何保证一致性,假设现在有一个场景:
客户端发送请求到Leader,Leader负责分发数据到Follower并且获得多数节点认可后进行提交,正常流程如下:
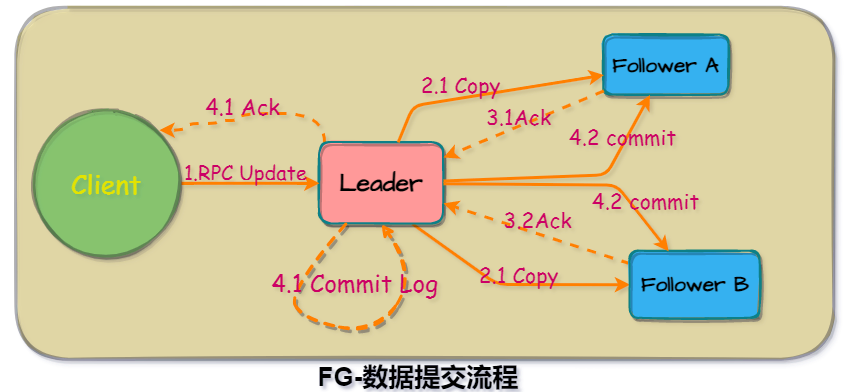
假如客户端更新过程出现了故障,那么不同的角色会怎么处理呢?
- Follower故障:Leader会不断的通过RPC请求确认Follower记录追上
- Leader故障:
Leader故障情况可以再次细分,在宕机时刻数据日志到达Leader之后,Follower是否提交的两种情况:- 数据到达Leader,且未提交到Follower,此时Leader宕机,Client未收到ACK,则会开启重试逻辑,在新的Leader恢复之后继续保证一致性。
- 数据到达Leader,部分Follower已经提交,此时Leader宕机,新的Leader将在已提交的部分Follower产生,因为他们的记录是最新的,再次竞选成功,成为新的Leader,最后进行一致性同步。
- Leader节点出现网络分区,在短时间内出现了“脑裂”,即网络分区无法联系对方,在2个局部网络产生了2个Leader,这时候在另一个分区中,新的Leader会选出,新的Leader term编号+1,等到网络分区恢复之后,由于新的Leader由于term编号比旧Leader大,因此最终会以TermId最大的新Leader的数据版本同步。
这里还有一个优化选项,etcd提供了一个PreVote参数,用来优化因为网络问题频繁Leader选举的情况,如果当前节点要变成Candidate竞选者,会有一个PreCandidate预投票的状态,如果预投票没有得到大多数节点的相应,则会放弃竞选。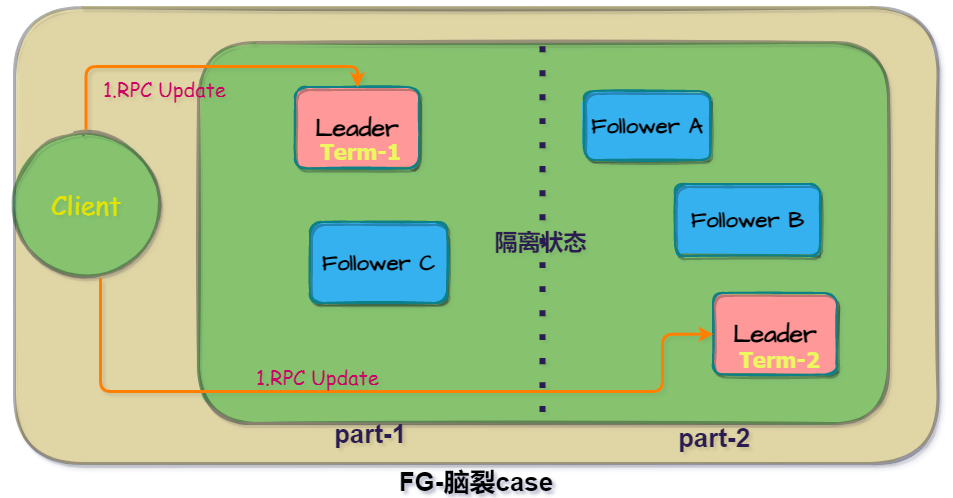
此外,针对脑裂的场景,etcd还提供了一个Leader自检查票数的开关
// CheckQuorum specifies if the leader should check quorum activity. Leader
// steps down when quorum is not active for an electionTimeout.
CheckQuorum bool
每隔一段时间,Leader从其他节点获得心跳并记录连接数,如果心跳连接数小于半数,Leader会自动降为Follower。
// tickHeartbeat is run by leaders to send a MsgBeat after r.heartbeatTimeout.
func (r *raft) tickHeartbeat() {
// ...
// 自检
if r.checkQuorum {
if err := r.Step(pb.Message{From: r.id, Type: pb.MsgCheckQuorum}); err != nil {
r.logger.Debugf("error occurred during checking sending heartbeat: %v", err)
}
}
//...
}
// Leader消息处理
func stepLeader(r *raft, m pb.Message) error {
// These message types do not require any progress for m.From.
switch m.Type {
// ...
case pb.MsgCheckQuorum:
// ...
// 检测Leader是否有大多数人票选
if !r.prs.QuorumActive() {
r.logger.Warningf("%x stepped down to follower since quorum is not active", r.id)
// 降为Follower
r.becomeFollower(r.Term, None)
}
// ...
}
// ...
}
线性读
在上面的网络分区故障场景中,我们知道了有可能有一段时间存在双Leader,即数据版本可能有脏数据。其实,在etcd数据集合上有一个最大提交下标CommitIndex,表示当前大多数节点认可的下标,ReadIndex表示当前节点可以获取的最新的下标(可能还没被大多数认可)。
etcd通过这两个记录,提供了是否开启线性读的选项(Serializable bool类型 ),用于阻塞读请求,在需要强一致性的情况下,开启线性读,请求则会等到Follower版本ReadIndex追上一致下标CommitIndex再返回数据,这个时候就能保证读到的记录是集群中一致ack的。
相关源码如下:
type RangeRequest struct {
// key is the first key for the range. If range_end is not given, the request only looks up key.
Key []byte `protobuf:"bytes,1,opt,name=key,proto3" json:"key,omitempty"`
// ...
// serializable sets the range request to use serializable member-local reads.
// Range requests are linearizable by default; linearizable requests have higher
// latency and lower throughput than serializable requests but reflect the current
// consensus of the cluster. For better performance, in exchange for possible stale reads,
// a serializable range request is served locally without needing to reach consensus
// with other nodes in the cluster.
Serializable bool
// ...
}
func (s *EtcdServer) Range(ctx context.Context, r *pb.RangeRequest) (*pb.RangeResponse, error) {
trace := traceutil.New("range",
s.Logger(),
traceutil.Field{Key: "range_begin", Value: string(r.Key)},
traceutil.Field{Key: "range_end", Value: string(r.RangeEnd)},
)
ctx = context.WithValue(ctx, traceutil.TraceKey, trace)
var resp *pb.RangeResponse
var err error
//...
if !r.Serializable {
// 线性读, 阻塞等待
err = s.linearizableReadNotify(ctx)
trace.Step("agreement among raft nodes before linearized reading")
if err != nil {
return nil, err
}
}
chk := func(ai *auth.AuthInfo) error {
return s.authStore.IsRangePermitted(ai, r.Key, r.RangeEnd)
}
get := func() { resp, err = txn.Range(ctx, s.Logger(), s.KV(), nil, r) }
if serr := s.doSerialize(ctx, chk, get); serr != nil {
err = serr
return nil, err
}
return resp, err
}
总结
这是这几天通过对etcd内部共识机制的一些理解,主要涉及选举状态转移、日志压缩等概念。本系列的下一篇章将聊一聊etcd节点是怎么通信的。
参考链接
- raft消息类型
https://pkg.go.dev/go.etcd.io/etcd/raft/v3#hdr-MessageType - etc技术内幕 - 百里燊
- 云原生分布式存储基石etcd深入解析 - 华为云